说明
本文以UE5中向渲染线程入队命令的宏ENQUEUE_RENDER_COMMAND,以及RDGPass Execute为例,进行渲染并行化的简要分析
ENQUEUE_RENDER_COMMAND 并行化
以往使用 ENQUEUE_RENDER_COMMAND 向渲染线程入队命令时,每一个 Enqueue 都会创建对应的任务并入队执行。
而ENQUEUE_RENDER_COMMAND 并行所做的优化概括来说就是:可以异步地将需要处理的Command加入FRenderThreadCommandPipe::Queue,然后在某些时候创建一个任务统一顺序执行完
ParallelFor
FRegisterComponentContext::Process 中使用多个线程并行地调用 FScene::AddPrimitive
// Engine\Source\Runtime\Engine\Private\Components\ActorComponent.cpp
void FRegisterComponentContext::Process()
{
(...)
ParallelFor(AddPrimitiveBatches.Num(),
[&](int32 Index)
{
FOptionalTaskTagScope Scope(ETaskTag::EParallelGameThread);
UPrimitiveComponent* Component = AddPrimitiveBatches[Index];
// AActor::PostRegisterAllComponents (called by AActor::IncrementalRegisterComponents) can trigger code
// that either unregisters or re-registers components. If unregistered, skip this component.
// If re-registered, FRegisterComponentContext is not passed, so SceneProxy can be created.
if (IsValid(Component) && Component->IsRegistered())
{
if (Component->IsRenderStateCreated() || !bAppCanEverRender)
{
// Skip if SceneProxy is already created
if (Component->SceneProxy == nullptr)
{
Scene->AddPrimitive(Component);
}
}
else // Fallback for some edge case where the component renderstate are missing
{
Component->CreateRenderState_Concurrent(nullptr);
}
}
},
bSingleThreaded
);
AddPrimitiveBatches.Empty();
(...)
}AddPrimitive
在 FScene::AddPrimitive 中调用 FScene::BatchAddPrimitivesInternal,并在最后使用 ENQUEUE_RENDER_COMMAND(AddPrimitiveCommand),将AddPrimiviteCommand 加入渲染线程队列
// Engine\Source\Runtime\Renderer\Private\RendererScene.cpp
void FScene::AddPrimitive(FPrimitiveSceneDesc* Primitive)
{
// If the bulk reregister flag is set, add / remove will be handled in bulk by the FStaticMeshComponentBulkReregisterContext
if (Primitive->bBulkReregister)
{
return;
}
BatchAddPrimitivesInternal(MakeArrayView(&Primitive, 1));
}
template<class T>
void FScene::BatchAddPrimitivesInternal(TArrayView<T*> InPrimitives)
{
(...)
for (T* Primitive : InPrimitives)
{
(...)
FPrimitiveSceneProxy* PrimitiveSceneProxy = nullptr;
(...)
// Create the primitive scene info.
FPrimitiveSceneInfo* PrimitiveSceneInfo = new FPrimitiveSceneInfo(Primitive, this);
PrimitiveSceneProxy->PrimitiveSceneInfo = PrimitiveSceneInfo;
// Cache the primitives initial transform.
FMatrix RenderMatrix = Primitive->GetRenderMatrix();
FVector AttachmentRootPosition = Primitive->GetActorPositionForRenderer();
CreateCommands.Emplace(
PrimitiveSceneInfo,
PrimitiveSceneProxy,
// If this primitive has a simulated previous transform, ensure that the velocity data for the scene representation is correct.
FMotionVectorSimulation::Get().GetPreviousTransform(ToUObject(Primitive)),
RenderMatrix,
Primitive->Bounds,
AttachmentRootPosition,
Primitive->GetLocalBounds()
);
(...)
}
if (!CreateCommands.IsEmpty())
{
ENQUEUE_RENDER_COMMAND(AddPrimitiveCommand)(
[this, CreateCommands = MoveTemp(CreateCommands)](FRHICommandListBase& RHICmdList)
{
for (const FCreateCommand& Command : CreateCommands)
{
FScopeCycleCounter Context(Command.PrimitiveSceneProxy->GetStatId());
Command.PrimitiveSceneProxy->SetTransform(RHICmdList, Command.RenderMatrix, Command.WorldBounds, Command.LocalBounds, Command.AttachmentRootPosition);
Command.PrimitiveSceneProxy->CreateRenderThreadResources(RHICmdList);
AddPrimitiveSceneInfo_RenderThread(Command.PrimitiveSceneInfo, Command.PreviousTransform);
}
});
}
}ENQUEUE_RENDER_COMMAND
将 ENQUEUE_RENDER_COMMAND 宏展开后为如下形式:
struct TSTR_AddPrimitiveCommand126
{
static const char* CStr() { return "AddPrimitiveCommand"; }
static const TCHAR* TStr() { return L"AddPrimitiveCommand"; }
};
using FRenderCommandTag_AddPrimitiveCommand126 = TRenderCommandTag<TSTR_AddPrimitiveCommand126>;
FRenderCommandPipe::Enqueue<FRenderCommandTag_AddPrimitiveCommand126>(
[this, CreateCommands = MoveTemp(CreateCommands)](FRHICommandListBase& RHICmdList)
{
for (const FCreateCommand& Command : CreateCommands)
{
FScopeCycleCounter Context(Command.PrimitiveSceneProxy->GetStatId());
Command.PrimitiveSceneProxy->SetTransform(RHICmdList, Command.RenderMatrix, Command.WorldBounds, Command.LocalBounds, Command.AttachmentRootPosition);
Command.PrimitiveSceneProxy->CreateRenderThreadResources(RHICmdList);
AddPrimitiveSceneInfo_RenderThread(Command.PrimitiveSceneInfo, Command.PreviousTransform);
}
});展开后的 ENQUEUE_RENDER_COMMAND 宏,调用FRenderCommandPipe::Enqueue,并在其中调用 EnqueueUniqueRenderCommand
// Engine\Source\Runtime\RenderCore\Public\RenderingThread.h
class FRenderCommandPipe
{
public:
(...)
template <typename RenderCommandTag, typename LambdaType>
FORCEINLINE static void Enqueue(LambdaType&& Lambda)
{
EnqueueUniqueRenderCommand<RenderCommandTag>(MoveTemp(Lambda));
}
(...)
}
template<typename RenderCommandTag, typename LambdaType>
FORCEINLINE_DEBUGGABLE void EnqueueUniqueRenderCommand(LambdaType&& Lambda)
{
TRACE_CPUPROFILER_EVENT_SCOPE_USE_ON_CHANNEL(RenderCommandTag::GetSpecId(), RenderCommandTag::GetName(), EventScope, RenderCommandsChannel, true);
// 如果在渲染线程内直接执行回调而不入队渲染命令.
if (IsInRenderingThread())
{
Lambda(GetImmediateCommandList_ForRenderCommand());
}
// 需要在独立的渲染线程执行
else if (ShouldExecuteOnRenderThread())
{
CheckNotBlockedOnRenderThread();
FRenderThreadCommandPipe::Enqueue<RenderCommandTag, LambdaType>(MoveTemp(Lambda));
}
// 不在独立的渲染线程执行, 则直接执行
else
{
FScopeCycleCounter CycleScope(RenderCommandTag::GetStatId());
Lambda(GetImmediateCommandList_ForRenderCommand());
}
}可见,若入队的命令需要在独立的渲染线程执行,则会调用 FRenderThreadCommandPipe::Enqueue
// Engine\Source\Runtime\RenderCore\Public\RenderingThread.h
class FRenderThreadCommandPipe
{
public:
template <typename RenderCommandTag, typename LambdaType>
FORCEINLINE_DEBUGGABLE static void Enqueue(LambdaType&& Lambda)
{
if (GRenderCommandPipeMode != ERenderCommandPipeMode::None)
{
Instance.EnqueueAndLaunch(RenderCommandTag::GetName(), RenderCommandTag::GetSpecId(), RenderCommandTag::GetStatId(), MoveTemp(Lambda));
}
else
{
TGraphTask<TEnqueueUniqueRenderCommandType<RenderCommandTag, LambdaType>>::CreateTask().ConstructAndDispatchWhenReady(MoveTemp(Lambda));
}
}
(...)
}若 RenderCommandPipe 处于活跃状态,则调用 FRenderThreadCommandPipe::EnqueueAndLaunch 来向渲染线程入队命令;否则将会绕过 RenderCommandPipe,使用如以往相同的未经优化的方式来入队
// Engine\Source\Runtime\RenderCore\Private\RenderingThread.cpp
void FRenderThreadCommandPipe::EnqueueAndLaunch(const TCHAR* Name, uint32& SpecId, TStatId StatId, TUniqueFunction<void(FRHICommandListImmediate&)>&& Function)
{
Mutex.Lock();
bool bWasEmpty = Queues[ProduceIndex].IsEmpty();
Queues[ProduceIndex].Emplace(Name, SpecId, StatId, MoveTemp(Function));
Mutex.Unlock();
if (bWasEmpty)
{
TGraphTask<TFunctionGraphTaskImpl<void(), ESubsequentsMode::FireAndForget>>::CreateTask().ConstructAndDispatchWhenReady([this]
{
FRHICommandListImmediate& RHICmdList = GetImmediateCommandList_ForRenderCommand();
Mutex.Lock();
TArray<FCommand>& ConsumeCommands = Queues[ProduceIndex];
ProduceIndex ^= 1;
Mutex.Unlock();
for (FCommand& Command : ConsumeCommands)
{
TRACE_CPUPROFILER_EVENT_SCOPE_USE_ON_CHANNEL(*Command.SpecId, Command.Name, EventScope, RenderCommandsChannel, true);
FScopeCycleCounter Scope(Command.StatId, true);
Command.Function(RHICmdList);
// Release the command immediately to match destruction order with task version.
Command.Function = {};
}
ConsumeCommands.Reset();
}, TStatId(), ENamedThreads::GetRenderThread());
}
}
FRenderThreadCommandPipe::Queues 相当于一个暂存命令的队列。
每次使用 ENQUEUE_RENDER_COMMAND 宏入队命令时,先暂缓任务的创建和入队,而是将命令暂存于 Queues 中。
Queues 包含两个队列,由 ProduceIndex 来回切换取得。
过程分析:
- 第一个入队的命令,会取到 bWasEmpty == true,然后将命令加入 Queues[ProduceIndex] ,于是会进入后面的 if 分支,在其中创建任务遍历 Queues[ProduceIndex] 中的命令在渲染线程执行;
- 注意到,上述执行命令的任务创建并入队,直到其真正被渲染线程执行前,Queues 都是未被当前线程上锁的,也就是说在此期间其他线程可以继续向 Queues[ProduceIndex] 暂存命令;
- 当任务在渲染线程被执行,加锁取得 Queues[ProduceIndex] 中的命令,并切换 ProduceIndex 到另一队列,然后解锁;
- 在任务执行时,取得的命令由渲染线程按加入的顺序依次执行。与此同时,其他入队命令的线程可以向 Queues[ProduceIndex] (另一个队列)暂存任务,并在合适的时机用同样的方式执行。
Unreal Insight Trace
使用Unreal Insight Trace一下ENQUEUE_RENDER_COMMAND的调用过程,以进一步加深理解

ExecutePass 并行化
以FDeferredShadingSceneRenderer中BasePass异步执行为例
AddPass
在 FDeferredShadingSceneRenderer::Render 中 AddPass
// Engine\Source\Runtime\Renderer\Private\BasePassRendering.cpp
void FDeferredShadingSceneRenderer::RenderBasePassInternal(
FRDGBuilder& GraphBuilder,
TArrayView<FViewInfo> InViews,
const FSceneTextures& SceneTextures,
const FRenderTargetBindingSlots& BasePassRenderTargets,
FExclusiveDepthStencil::Type BasePassDepthStencilAccess,
const FForwardBasePassTextures& ForwardBasePassTextures,
const FDBufferTextures& DBufferTextures,
bool bParallelBasePass,
bool bRenderLightmapDensity,
FInstanceCullingManager& InstanceCullingManager,
bool bNaniteEnabled,
FNaniteShadingCommands& NaniteBasePassShadingCommands,
const TArrayView<Nanite::FRasterResults>& NaniteRasterResults)
{
(...)
if (bRenderLightmapDensity || ViewFamily.UseDebugViewPS())
{
(...)
}
else
{
(...)
if (bParallelBasePass)
{
RDG_WAIT_FOR_TASKS_CONDITIONAL(GraphBuilder, IsBasePassWaitForTasksEnabled());
for (int32 ViewIndex = 0; ViewIndex < InViews.Num(); ++ViewIndex)
{
(...)
if (bShouldRenderView)
{
View.ParallelMeshDrawCommandPasses[EMeshPass::BasePass].BuildRenderingCommands(GraphBuilder, Scene->GPUScene, PassParameters->InstanceCullingDrawParams);
GraphBuilder.AddPass(
RDG_EVENT_NAME("BasePassParallel"),
PassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
[this, &View, PassParameters](const FRDGPass* InPass, FRHICommandListImmediate& RHICmdList)
{
FRDGParallelCommandListSet ParallelCommandListSet(InPass, RHICmdList, GET_STATID(STAT_CLP_BasePass), View, FParallelCommandListBindings(PassParameters));
View.ParallelMeshDrawCommandPasses[EMeshPass::BasePass].DispatchDraw(&ParallelCommandListSet, RHICmdList, &PassParameters->InstanceCullingDrawParams);
});
}
(...)
}
(...)
}
(...)
}
(...)
}当上述 Pass 执行时,会先创建 FRDGParallelCommandListSet,然后将其传入 FParallelMeshDrawCommandPass::DispatchDraw
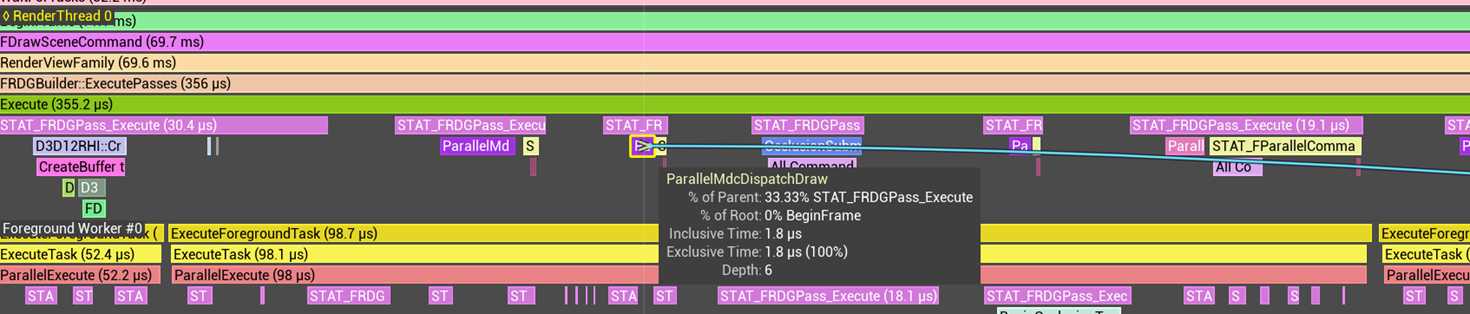
DispatchDraw
在 FParallelMeshDrawCommandPass::DispatchDraw 中,创建与工作线程数量相同的任务数,将 Draws 均匀分配给各个任务
具体而言,分别为每个工作线程创建 FDrawVisibleMeshCommandsAnyThreadTask 并加入其中,然后为 ParallelCommandListSet 添加新的并行命令队列,并记录命令队列对应的 NumDraws
// Engine\Source\Runtime\Renderer\Private\MeshDrawCommands.cpp
void FParallelMeshDrawCommandPass::DispatchDraw(FParallelCommandListSet* ParallelCommandListSet, FRHICommandList& RHICmdList, const FInstanceCullingDrawParams* InstanceCullingDrawParams) const
{
(...)
if (ParallelCommandListSet)
{
const ENamedThreads::Type RenderThread = ENamedThreads::GetRenderThread();
// 处理前序任务
FGraphEventArray Prereqs;
if (ParallelCommandListSet->GetPrereqs())
{
Prereqs.Append(*ParallelCommandListSet->GetPrereqs());
}
if (TaskEventRef.IsValid())
{
Prereqs.Add(TaskEventRef);
}
// 构造与工作线程数量相同的并行绘制任务数
const int32 NumThreads = FMath::Min<int32>(FTaskGraphInterface::Get().GetNumWorkerThreads(), ParallelCommandListSet->Width);
const int32 NumTasks = FMath::Min<int32>(NumThreads, FMath::DivideAndRoundUp(MaxNumDraws, ParallelCommandListSet->MinDrawsPerCommandList));
const int32 NumDrawsPerTask = FMath::DivideAndRoundUp(MaxNumDraws, NumTasks);
// 遍历NumTasks次,构造NumTasks个绘制任务(FDrawVisibleMeshCommandsAnyThreadTask)实例
for (int32 TaskIndex = 0; TaskIndex < NumTasks; TaskIndex++)
{
const int32 StartIndex = TaskIndex * NumDrawsPerTask;
const int32 NumDraws = FMath::Min(NumDrawsPerTask, MaxNumDraws - StartIndex);
checkSlow(NumDraws > 0);
// 新建命令队列
FRHICommandList* CmdList = ParallelCommandListSet->NewParallelCommandList();
// 构造FDrawVisibleMeshCommandsAnyThreadTask实例并加入TaskGraph中
// 其中TaskContext.MeshDrawCommands就是上一部分由FMeshPassProcessor生成的
FGraphEventRef AnyThreadCompletionEvent = TGraphTask<FDrawVisibleMeshCommandsAnyThreadTask>::CreateTask(&Prereqs, RenderThread)
.ConstructAndDispatchWhenReady(*CmdList, TaskContext.InstanceCullingContext, TaskContext.MeshDrawCommands, TaskContext.MinimalPipelineStatePassSet,
OverrideArgs,
TaskContext.InstanceFactor,
TaskIndex, NumTasks);
ParallelCommandListSet->AddParallelCommandList(CmdList, AnyThreadCompletionEvent, NumDraws);
}
}
else
{
(...)
}
}
// Engine\Source\Runtime\Renderer\Private\SceneRendering.cpp
void FParallelCommandListSet::AddParallelCommandList(FRHICommandList* CmdList, FGraphEventRef& /*unused CompletionEvent*/, int32 InNumDrawsIfKnown)
{
QueuedCommandLists.Emplace(CmdList, InNumDrawsIfKnown >= 0 ? TOptional<uint32>(InNumDrawsIfKnown) : TOptional<uint32>());
}
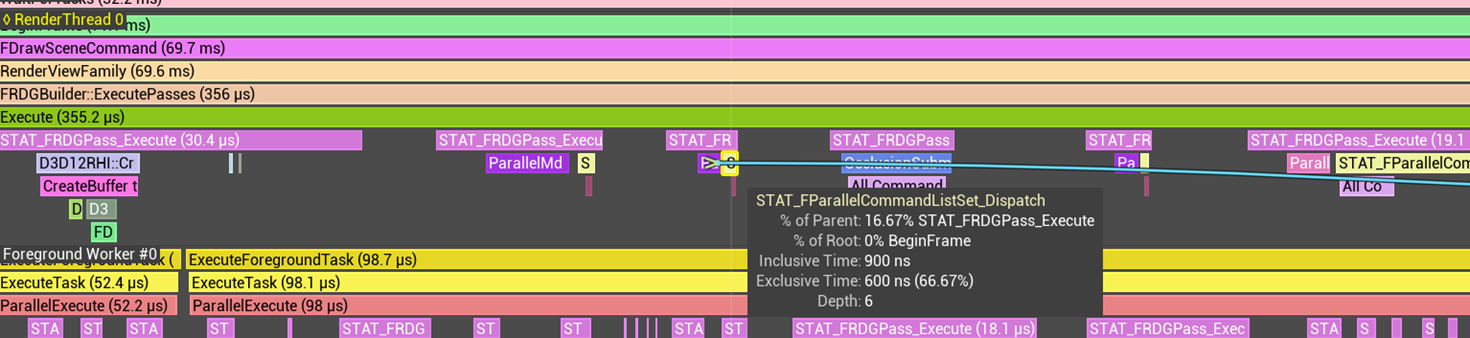
分发命令队列
当上述 Pass 的 Lambda 执行完毕,ParallelCommandListSet 会被析构,在其析构函数中调用 FParallelCommandListSet::Dispatch
// Engine\Source\Runtime\Renderer\Private\SceneRendering.h
class FRDGParallelCommandListSet final : public FParallelCommandListSet
{
public:
(...)
~FRDGParallelCommandListSet() override
{
Dispatch(bHighPriority);
}
(...)
};
// Engine\Source\Runtime\Renderer\Private\SceneRendering.cpp
void FParallelCommandListSet::Dispatch(bool bHighPriority)
{
(...)
bool bActuallyDoParallelTranslate = GRHISupportsParallelRHIExecute && QueuedCommandLists.Num() >= CVarRHICmdMinCmdlistForParallelSubmit.GetValueOnRenderThread();
(...)
if (bActuallyDoParallelTranslate)
{
check(GRHISupportsParallelRHIExecute);
auto Priority = bHighPriority
? FRHICommandListImmediate::ETranslatePriority::High
: FRHICommandListImmediate::ETranslatePriority::Normal;
NumAlloc -= QueuedCommandLists.Num();
ParentCmdList.QueueAsyncCommandListSubmit(QueuedCommandLists, Priority, (MinDrawsPerCommandList * 4) / 3);
// #todo-renderpasses PS4 breaks if this isn't here. Why?
SetStateOnCommandList(ParentCmdList);
if (bHasRenderPasses)
{
ParentCmdList.EndRenderPass();
}
}
else
{
(...)
}
QueuedCommandLists.Reset();
QUICK_SCOPE_CYCLE_COUNTER(STAT_FParallelCommandListSet_Dispatch_ServiceLocalQueue);
FTaskGraphInterface::Get().ProcessThreadUntilIdle(RenderThread_Local);
}
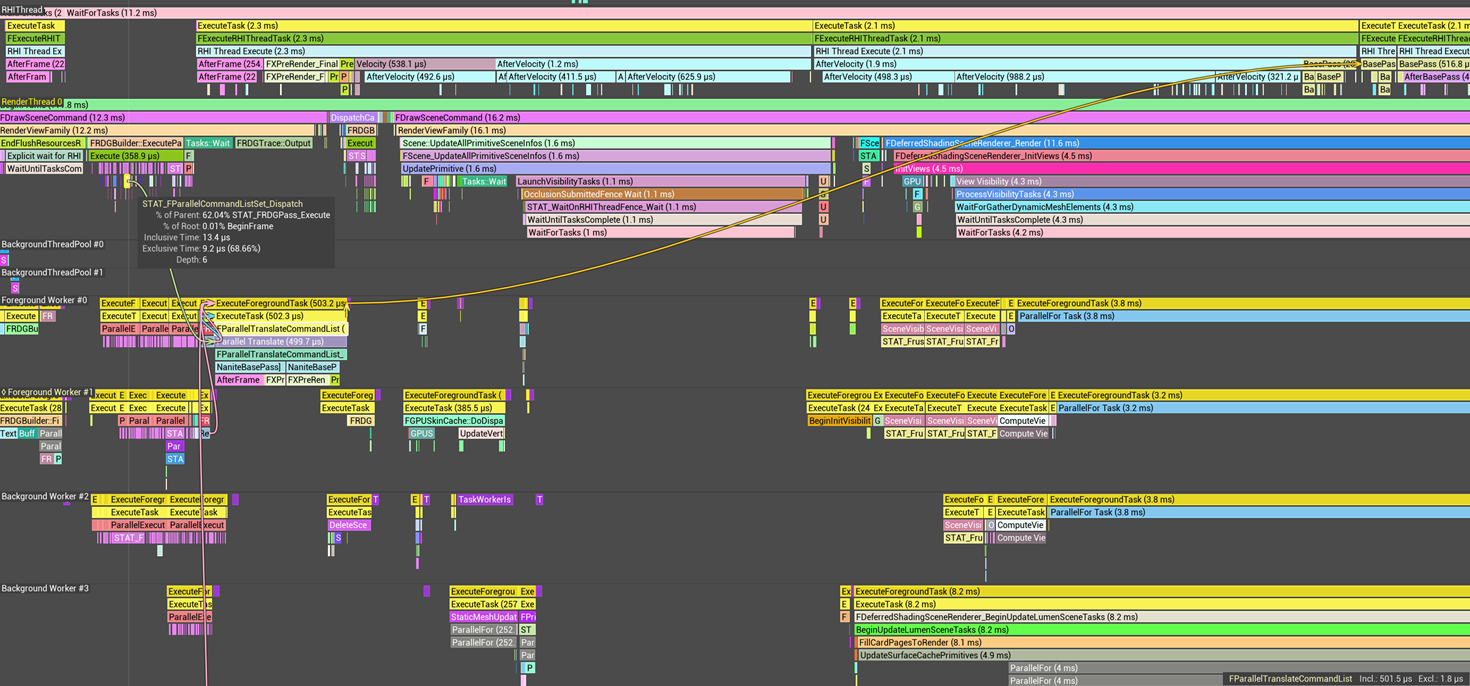
并行转译
在 FParallelCommandListSet::Dispatch 中会调用 FRHICommandListImmediate::QueueAsyncCommandListSubmit 异步地将 MeshDrawCommand 转译为 RHICommand,加入到 RHICommandList 中
其中主要完成:执行 RHICommandList 中剩余在排队的命令;命令队列合并转译的计算;前序事件收集;处理图形API同步;创建并分发并行转译任务;按顺序提交转译得到的 RHIPlatformCommandList;
添加一个 RHI 线程任务来提交已完成的平台命令列表。
每个并行翻译完成的任务块,按照提交的顺序排列。
// Engine\Source\Runtime\RHI\Private\RHICommandList.cpp
void FRHICommandListImmediate::QueueAsyncCommandListSubmit(TArrayView<FQueuedCommandList> CommandLists, ETranslatePriority ParallelTranslatePriority, int32 MinDrawsPerTranslate)
{
(...)
if (ParallelTranslatePriority != ETranslatePriority::Disabled && GRHISupportsParallelRHIExecute && IsRunningRHIInSeparateThread())
{
// 在转译开始前,RHICommandList 中可能还有命令正在排队,为防止加入新转译的命令后乱序执行
// 需要先将 RHICommandList 中的命令执行完毕
ExecuteAndReset(false);
InitializeImmediateContexts();
(...)
for (int32 RangeStart = 0, RangeEnd = 0; RangeStart < CommandLists.Num(); RangeStart = RangeEnd)
{
RangeEnd = RangeStart + 1;
// 遍历需要转译的命令队列,检查其 NumDraws 是否达到 MinDrawsPerTranslate
// 如果达到则单独转译该命令队列
// 如果未到达则需要与后续的命令队列合并转译。
if (bMerge)
{
for (int32 NumDraws = 0, Index = RangeStart; Index < CommandLists.Num(); ++Index)
{
// Command lists without NumDraws set are translated on their own
if (!CommandLists[Index].NumDraws.IsSet())
break;
// Otherwise group command lists into batches to reach at least MinDrawsPerTranslate
NumDraws += CommandLists[Index].NumDraws.GetValue();
RangeEnd = Index + 1;
if (NumDraws >= MinDrawsPerTranslate)
break;
}
}
const int32 NumCmdListsInBatch = RangeEnd - RangeStart;
FTask& Task = *(new (&Tasks[NumTasks++]) FTask());
Task.InCmdLists = AllocArrayUninitialized<FRHICommandListBase*>(NumCmdListsInBatch);
// 对于每一批需要转译的命令队列,收集其前序事件
FGraphEventArray Prereqs;
for (int32 Index = 0; Index < NumCmdListsInBatch; ++Index)
{
FRHICommandListBase* CmdList = CommandLists[RangeStart + Index].CmdList;
Task.InCmdLists[Index] = CmdList;
Prereqs.Add(CmdList->DispatchEvent);
}
// 与图形API同步
if (PersistentState.QueuedFenceCandidates.Num() > 0)
{
FGraphEventRef FenceCandidateEvent = FGraphEvent::CreateGraphEvent();
if (PersistentState.RHIThreadBufferLockFence.GetReference())
{
FenceCandidateEvent->DontCompleteUntil(PersistentState.RHIThreadBufferLockFence);
}
PersistentState.RHIThreadBufferLockFence = FenceCandidateEvent;
Prereqs.Add(FenceCandidateEvent);
FFunctionGraphTask::CreateAndDispatchWhenReady(
[FenceCandidates = MoveTemp(PersistentState.QueuedFenceCandidates), FenceCandidateEvent](ENamedThreads::Type, const FGraphEventRef&) mutable
{
SCOPED_NAMED_EVENT(FRHICommandListBase_SignalLockFence, FColor::Magenta);
for (int32 Index = FenceCandidates.Num() - 1; Index >= 0; Index--)
{
if (FenceCandidates[Index]->Fence)
{
FenceCandidateEvent->DontCompleteUntil(FenceCandidates[Index]->Fence);
break;
}
}
FenceCandidateEvent->DispatchSubsequents();
}, TStatId(), &PersistentState.QueuedFenceCandidateEvents);
PersistentState.QueuedFenceCandidateEvents.Reset();
}
else if (PersistentState.RHIThreadBufferLockFence)
{
Prereqs.Add(PersistentState.RHIThreadBufferLockFence);
}
// 创建并分发并行转译任务
Task.Event = FFunctionGraphTask::CreateAndDispatchWhenReady(
[&Task, GPUStatsInitial = PersistentState.Stats]()
{
FOptionalTaskTagScope Scope(ETaskTag::EParallelRhiThread);
SCOPE_CYCLE_COUNTER(STAT_ParallelTranslate);
SCOPED_NAMED_EVENT(FParallelTranslateCommandList_DoTask, FColor::Magenta);
TRHIPipelineArray<IRHIComputeContext*> Contexts = {};
// Replay the recorded commands. The Contexts array accumulates any used
// contexts depending on the SwitchPipeline commands that were recorded.
for (FRHICommandListBase* RHICmdList : Task.InCmdLists)
{
// Redirect the output stats to this parallel task's copy
FPersistentState::FGPUStats Stats = GPUStatsInitial;
Stats.Ptr = &Task.Stats;
RHICmdList->Execute(Contexts, &Stats);
delete RHICmdList;
}
// Convert the completed contexts into IRHIPlatformCommandList instances.
// These are submitted by the RHI thread waiting on this translate task.
for (IRHIComputeContext* Context : Contexts)
{
if (Context)
{
IRHIPlatformCommandList* CommandList = GDynamicRHI->RHIFinalizeContext(Context);
if (CommandList)
{
Task.OutCmdLists.Add(CommandList);
}
}
}
}
, QUICK_USE_CYCLE_STAT(FParallelTranslateCommandList, STATGROUP_TaskGraphTasks)
, &Prereqs
, ParallelTranslatePriority == ETranslatePriority::High
? CPrio_FParallelTranslateCommandListPrepass.Get()
: CPrio_FParallelTranslateCommandList.Get()
);
}
// Resize the tasks array view to how many tasks we actually created after merging
Tasks = TArrayView<FTask>(Tasks.GetData(), NumTasks);
// 最后创建RHI线程任务,提交转译得到的RHIPlatformCommandList
// 将会按顺序提交
EnqueueLambda(TEXT("SubmitParallelCommandLists"), [Tasks](FRHICommandListBase& ExecutingCmdList)
{
TArray<IRHIPlatformCommandList*> AllCmdLists;
for (FTask& Task : Tasks)
{
if (!Task.Event->IsComplete())
{
SCOPE_CYCLE_COUNTER(STAT_ParallelTranslateWait);
Task.Event->Wait();
}
AllCmdLists.Append(Task.OutCmdLists);
ExecutingCmdList.PersistentState.Stats.Ptr->Accumulate(Task.Stats);
Task.~FTask();
}
if (AllCmdLists.Num())
{
GDynamicRHI->RHISubmitCommandLists(AllCmdLists, false);
}
});
}
else
{
// Commands will be executed directly on the RHI thread / default contexts
(...)
}
}
Reference
Unreal Engine Documentation: Parallel Rendering Overview