概述
RHI封装了众多图形API(DirectX、OpenGL、Vulkan、Metal)之间的差异,为Game和Renderer模块提供了简便且一致的概念、数据、资源和接口,实现一份渲染代码跑在多个平台的目标。
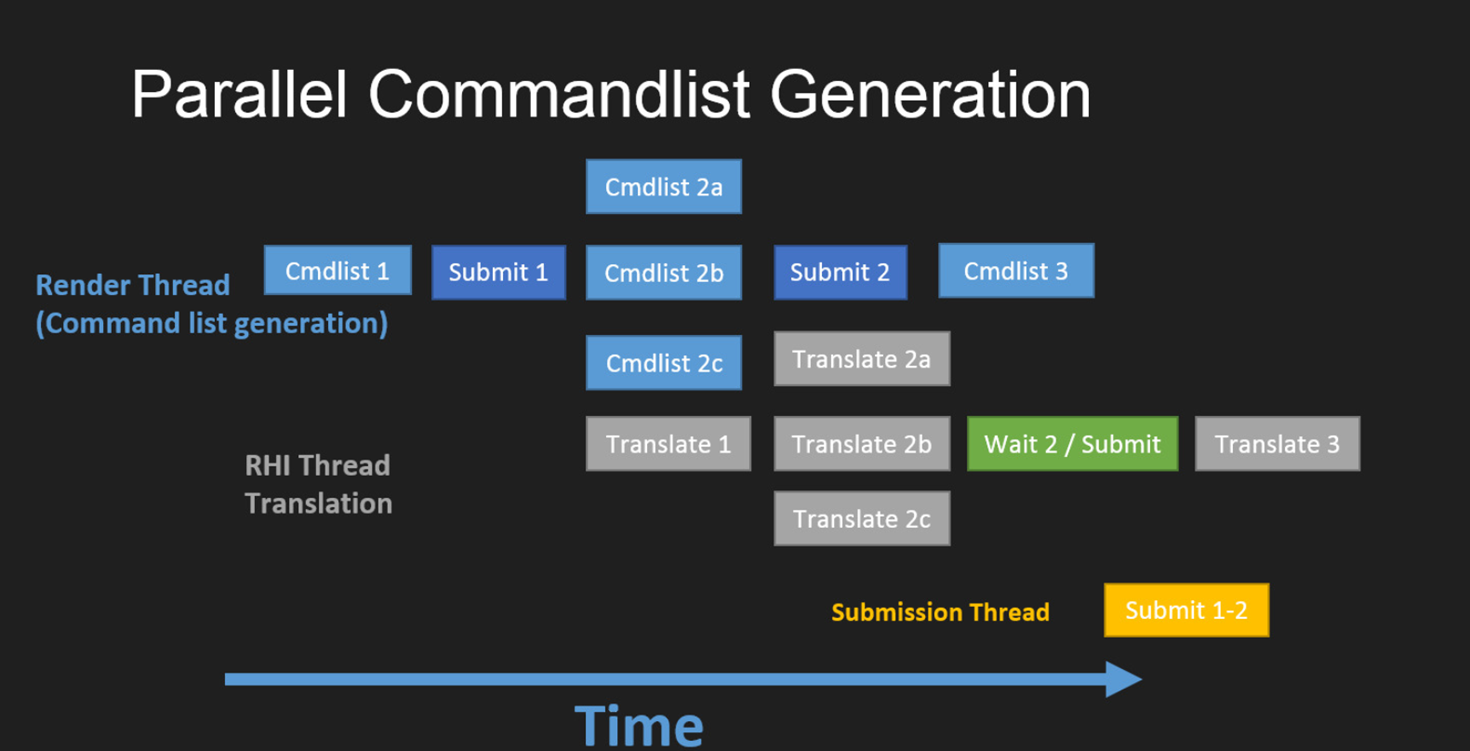
RHI线程的工作是将渲染线程生成的RHI中间指令转译到对应指定图形API的GPU指令。如果渲染线程是并行生成的RHI中间指令,那么RHI线程也会并行转译。
同步
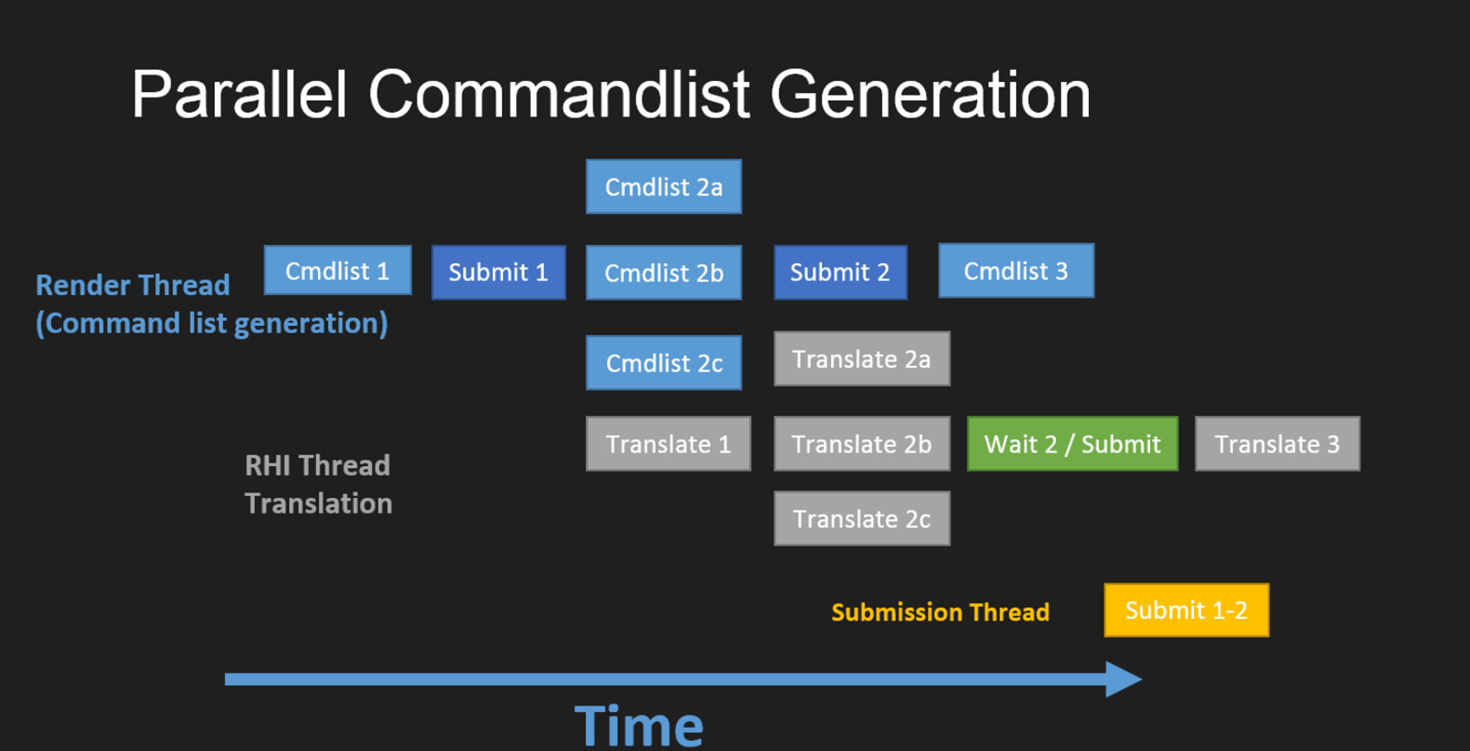
UE的渲染流程中,最多存在4种工作线程:游戏线程(Game Thread)、渲染线程(Render Thread)、RHI线程和GPU。
游戏线程是整个引擎的驱动者,提供所有的源数据和事件,以驱动渲染线程和RHI线程。游戏线程领先渲染线程不超过1帧,更具体地说如果第N帧的渲染线程在第N+1帧的游戏线程的Tick结束时还没有完成,那么游戏线程会被渲染线程卡住。反之,如果游戏线程负载过重,没能及时发送事件和数据给渲染线程,也会导致渲染线程卡住。
渲染线程负责产生RHI的中间命令,在适当的时机派发、刷新指令到RHI线程。因此,渲染线程的卡顿也可能导致RHI的卡顿。
RHI线程负责派发、转译、提交指令,且渲染的最后一步需要SwapBuffer,这一步需要等待GPU完成渲染工作。因此,渲染GPU的繁忙也会导致RHI线程的卡顿。
实现
基本类型
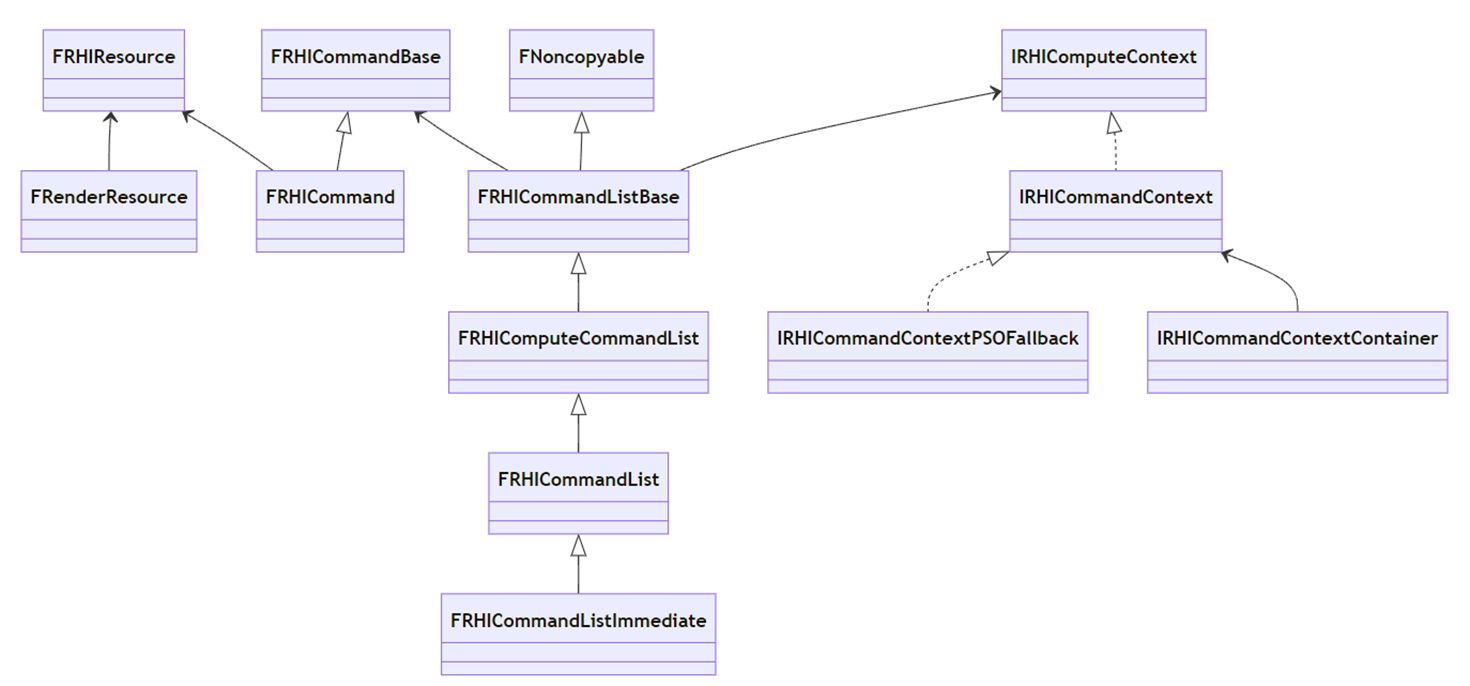
RHIResource
FRHIResource抽象了GPU侧的资源,也是各类RHI资源类型的父类。FRHIResource提供了:引用计数、延迟删除及追踪、运行时数据和标记等功能。其子类包括各种State资源、Shader、Uniform Buffer、Texture等。
RHICommand
FRHICommand是RHI模块的渲染指令基类,这些指令通常由渲染线程通过命令队列Push到RHI线程,在合适的时机由RHI线程执行。
FRHICommandListBase定义了命令队列所需的基本数据(命令列表、设备上下文)和接口(命令的刷新、等待、入队、派发等)。
FRHIComputeCommandList继承自FRHICommandListBase,定义了计算着色器相关的接口、GPU资源状态转换和着色器部分参数的设置。
FRHICommandList继承自FRHIComputeCommandList,定义了普通渲染管线的接口,包含VS、PS、GS的绑定,图元绘制,更多着色器参数的设置和资源状态转换,资源创建、更新和等待等。
FRHICommandContext & FDynamicRHI
IRHICommandContext是RHI的命令上下文接口类,定义了一组图形API相关的操作。FDynamicRHI是由动态绑定的RHI实现的接口。
传统图形API(D3D11、OpenGL)除了继承FDynamicRHI,还需要继承IRHICommandContextPSOFallback,因为需要借助后者的接口处理PSO的数据和行为,以保证传统和现代API对PSO的一致处理行为。而现代图形API(D3D12、Vulkan、Metal)不需要继承IRHICommandContext的任何继承体系的类型,单单直接继承FDynamicRHI就可以处理RHI层的所有数据和操作。
RHI命令执行
- 首先调用 FRHICommandList::DrawPrimitive,在其中根据是否开启Bypass进行不同处理。
- 若开启ByPass,则FRHICommandList将直接调用图形API上下文的接口,相当于同步调用图形API,此时的图形API运行于渲染线程
- 若未开启ByPass,则使用ALLOC_COMMAND宏构造 FRHICommandDrawPrimitive 命令,ALLOC_COMMAND展开后实际上是一个placement new,并且其中使用FRHICOMMAND_MACRO宏构造的FRHICommandDrawPrimitive命令,该命令并不会立即执行,而是通过placement new加入FRHICommandListBase维护的命令链表。
// Engine\Source\Runtime\RHI\Public\RHICommandList.h
class FRHICommandList : public FRHIComputeCommandList
{
public:
(...)
FORCEINLINE_DEBUGGABLE void DrawPrimitive(uint32 BaseVertexIndex, uint32 NumPrimitives, uint32 NumInstances)
{
//check(IsOutsideRenderPass());
if (Bypass())
{
GetContext().RHIDrawPrimitive(BaseVertexIndex, NumPrimitives, NumInstances);
return;
}
ALLOC_COMMAND(FRHICommandDrawPrimitive)(BaseVertexIndex, NumPrimitives, NumInstances);
}
(...)
};
FRHICOMMAND_MACRO(FRHICommandDrawPrimitive)
{
uint32 BaseVertexIndex;
uint32 NumPrimitives;
uint32 NumInstances;
FORCEINLINE_DEBUGGABLE FRHICommandDrawPrimitive(uint32 InBaseVertexIndex, uint32 InNumPrimitives, uint32 InNumInstances)
: BaseVertexIndex(InBaseVertexIndex)
, NumPrimitives(InNumPrimitives)
, NumInstances(InNumInstances)
{
}
RHI_API void Execute(FRHICommandListBase& CmdList);
};- FRHICommandDrawPrimitive::Execute
void FRHICommandDrawPrimitive::Execute(FRHICommandListBase& CmdList)
{
RHISTAT(DrawPrimitive);
INTERNAL_DECORATOR(RHIDrawPrimitive)(BaseVertexIndex, NumPrimitives, NumInstances);
}其中调用对应IRHICommandContext的RHIDrawPrimitive函数,例如:
FD3D12CommandContextRedirector::RHIDrawPrimitive --> FD3D12CommandContext::RHIDrawPrimitive
并行执行
FParallelCommandListSet
// Engine\Source\Runtime\Renderer\Private\SceneRendering.h
class FParallelCommandListSet
{
public:
const FRDGPass* Pass; // RDG Pass
const FViewInfo& View; // 所属的视图
FRHICommandListImmediate& ParentCmdList; // 父命令队列
TStatId ExecuteStat;
int32 Width;
int32 NumAlloc;
int32 MinDrawsPerCommandList;
private:
// 命令队列列表
TArray<FRHICommandListImmediate::FQueuedCommandList, SceneRenderingAllocator> QueuedCommandLists;
protected:
// 派发, 须由子类调用
void Dispatch(bool bHighPriority = false);
FRHICommandList* AllocCommandList();
bool bHasRenderPasses;
public:
FParallelCommandListSet(const FRDGPass* InPass, TStatId InExecuteStat, const FViewInfo& InView, FRHICommandListImmediate& InParentCmdList, bool bHasRenderPasses = true);
virtual ~FParallelCommandListSet();
int32 NumParallelCommandLists() const // 获取命令队列数量
{
return QueuedCommandLists.Num();
}
FRHICommandList* NewParallelCommandList(); // 新建一个并行的命令队列
FORCEINLINE FGraphEventArray* GetPrereqs() // 获取前序任务
{
return nullptr;
}
// 增加并行的命令队列
void AddParallelCommandList(FRHICommandList* CmdList, FGraphEventRef& CompletionEvent, int32 InNumDrawsIfKnown = -1);
virtual void SetStateOnCommandList(FRHICommandList& CmdList) {}
};并行执行过程
以UE Mesh Drawing Pipeline中FDeferredShadingSceneRenderer::RenderPrePass为例
在其中构造FRDGParallelCommandListSet(FParallelCommandListSet的子类)实例,然后ParallelMeshDrawCommandPasses::DispatchDraw,以FRDGParallelCommandListSet实例为参数传入。
// Engine\Source\Runtime\Renderer\Private\DepthRendering.cpp
void FDeferredShadingSceneRenderer::RenderPrePass(FRDGBuilder& GraphBuilder, TArrayView<FViewInfo> InViews, FRDGTextureRef SceneDepthTexture, FInstanceCullingManager& InstanceCullingManager, FRDGTextureRef* FirstStageDepthBuffer)
{
(...)
const bool bParallelDepthPass = GRHICommandList.UseParallelAlgorithms() && CVarParallelPrePass.GetValueOnRenderThread();
(...)
auto RenderDepthPass = [&](uint8 DepthMeshPass)
{
check(DepthMeshPass == EMeshPass::DepthPass || DepthMeshPass == EMeshPass::SecondStageDepthPass);
const bool bSecondStageDepthPass = DepthMeshPass == EMeshPass::SecondStageDepthPass;
if (bParallelDepthPass)
{
RDG_WAIT_FOR_TASKS_CONDITIONAL(GraphBuilder, IsDepthPassWaitForTasksEnabled());
// 遍历所有view,每个view都渲染一次深度Pass
for (int32 ViewIndex = 0; ViewIndex < InViews.Num(); ++ViewIndex)
{
FViewInfo& View = InViews[ViewIndex];
// 处理深度Pass的渲染资源和状态。
RDG_GPU_MASK_SCOPE(GraphBuilder, View.GPUMask);
RDG_EVENT_SCOPE_CONDITIONAL(GraphBuilder, InViews.Num() > 1, "View%d", ViewIndex);
FMeshPassProcessorRenderState DrawRenderState;
SetupDepthPassState(DrawRenderState);
const bool bShouldRenderView = View.ShouldRenderView() && (bSecondStageDepthPass ? View.bUsesSecondStageDepthPass : true);
if (bShouldRenderView)
{
View.BeginRenderView();
FDepthPassParameters* PassParameters = GetDepthPassParameters(GraphBuilder, View, SceneDepthTexture);
View.ParallelMeshDrawCommandPasses[DepthMeshPass].BuildRenderingCommands(GraphBuilder, Scene->GPUScene, PassParameters->InstanceCullingDrawParams);
GraphBuilder.AddPass(
bSecondStageDepthPass ? RDG_EVENT_NAME("SecondStageDepthPassParallel") : RDG_EVENT_NAME("DepthPassParallel"),
PassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
[this, &View, PassParameters, DepthMeshPass](const FRDGPass* InPass, FRHICommandListImmediate& RHICmdList)
{
// 构造绘制指令存储容器
FRDGParallelCommandListSet ParallelCommandListSet(InPass, RHICmdList, GET_STATID(STAT_CLP_Prepass), View, FParallelCommandListBindings(PassParameters));
ParallelCommandListSet.SetHighPriority();
// 触发并行绘制
View.ParallelMeshDrawCommandPasses[DepthMeshPass].DispatchDraw(&ParallelCommandListSet, RHICmdList, &PassParameters->InstanceCullingDrawParams);
});
RenderPrePassEditorPrimitives(GraphBuilder, View, PassParameters, DrawRenderState, DepthPass.EarlyZPassMode, InstanceCullingManager);
}
}
}
else
{
(...)
}
};
(...)
}在ParallelMeshDrawCommandPasses::DispatchDraw中,利用传入的FRDGParallelCommandListSet处理前序任务,并构建新的命令队列,用此作为参数之一,构建任务FDrawVisibleMeshCommandsAnyThreadTask,并获得事件对象,并添加事件到FRDGParallelCommandListSet实例中
// Engine\Source\Runtime\Renderer\Private\MeshDrawCommands.cpp
void FParallelMeshDrawCommandPass::DispatchDraw(FParallelCommandListSet* ParallelCommandListSet, FRHICommandList& RHICmdList, const FInstanceCullingDrawParams* InstanceCullingDrawParams) const
{
(...)
if (ParallelCommandListSet)
{
const ENamedThreads::Type RenderThread = ENamedThreads::GetRenderThread();
// 处理前序任务
FGraphEventArray Prereqs;
if (ParallelCommandListSet->GetPrereqs())
{
Prereqs.Append(*ParallelCommandListSet->GetPrereqs());
}
if (TaskEventRef.IsValid())
{
Prereqs.Add(TaskEventRef);
}
// 构造与工作线程数量相同的并行绘制任务数
const int32 NumThreads = FMath::Min<int32>(FTaskGraphInterface::Get().GetNumWorkerThreads(), ParallelCommandListSet->Width);
const int32 NumTasks = FMath::Min<int32>(NumThreads, FMath::DivideAndRoundUp(MaxNumDraws, ParallelCommandListSet->MinDrawsPerCommandList));
const int32 NumDrawsPerTask = FMath::DivideAndRoundUp(MaxNumDraws, NumTasks);
// 遍历NumTasks次,构造NumTasks个绘制任务(FDrawVisibleMeshCommandsAnyThreadTask)实例
for (int32 TaskIndex = 0; TaskIndex < NumTasks; TaskIndex++)
{
const int32 StartIndex = TaskIndex * NumDrawsPerTask;
const int32 NumDraws = FMath::Min(NumDrawsPerTask, MaxNumDraws - StartIndex);
checkSlow(NumDraws > 0);
// 新建命令队列
FRHICommandList* CmdList = ParallelCommandListSet->NewParallelCommandList();
// 构造FDrawVisibleMeshCommandsAnyThreadTask实例并加入TaskGraph中
// 其中TaskContext.MeshDrawCommands就是上一部分由FMeshPassProcessor生成的
FGraphEventRef AnyThreadCompletionEvent = TGraphTask<FDrawVisibleMeshCommandsAnyThreadTask>::CreateTask(&Prereqs, RenderThread)
.ConstructAndDispatchWhenReady(*CmdList, TaskContext.InstanceCullingContext, TaskContext.MeshDrawCommands, TaskContext.MinimalPipelineStatePassSet,
OverrideArgs,
TaskContext.InstanceFactor,
TaskIndex, NumTasks);
// 将事件加入ParallelCommandListSet,以便追踪深度Pass的并行绘制是否完成。
ParallelCommandListSet->AddParallelCommandList(CmdList, AnyThreadCompletionEvent, NumDraws);
}
}
else
{
(...)
}
}当FRDGParallelCommandListSet被析构时,会调用其Dispatch函数真正地分发命令队列。
// Engine\Source\Runtime\Renderer\Private\SceneRendering.h
class FRDGParallelCommandListSet final : public FParallelCommandListSet
{
public:
~FRDGParallelCommandListSet() override
{
Dispatch(bHighPriority);
}
(...)
}
// Engine\Source\Runtime\Renderer\Private\SceneRendering.cpp
void FParallelCommandListSet::Dispatch(bool bHighPriority)
{
(...)
if (bActuallyDoParallelTranslate)
{
check(GRHISupportsParallelRHIExecute);
auto Priority = bHighPriority
? FRHICommandListImmediate::ETranslatePriority::High
: FRHICommandListImmediate::ETranslatePriority::Normal;
NumAlloc -= QueuedCommandLists.Num();
ParentCmdList.QueueAsyncCommandListSubmit(QueuedCommandLists, Priority, (MinDrawsPerCommandList * 4) / 3);
// #todo-renderpasses PS4 breaks if this isn't here. Why?
SetStateOnCommandList(ParentCmdList);
if (bHasRenderPasses)
{
ParentCmdList.EndRenderPass();
}
}
else
{
NumAlloc -= QueuedCommandLists.Num();
ParentCmdList.QueueAsyncCommandListSubmit(QueuedCommandLists);
}
QueuedCommandLists.Reset();
(...)
}随后进入FRHICommandListImmediate::QueueAsyncCommandListSubmit,完成并行Translate任务的创建和入队
注:UE4.26中的FParallelTranslateSetupCommandList类(设置Translate的任务)和FParallelTranslateCommandList类(真正的Translate命令队列),在UE5中已被去除。UE4中FRHICommandListBase::QueueParallelAsyncCommandListSubmit依赖上述两个类完成工作,而在UE5的FRHICommandListImmediate::QueueAsyncCommandListSubmit中直接写成了Lambda
// Engine\Source\Runtime\RHI\Private\RHICommandList.cpp
void FRHICommandListImmediate::QueueAsyncCommandListSubmit(TArrayView<FQueuedCommandList> CommandLists, ETranslatePriority ParallelTranslatePriority, int32 MinDrawsPerTranslate)
{
check(IsInRenderingThread());
if (CommandLists.Num() == 0)
return;
for (FQueuedCommandList const& QueuedCmdList : CommandLists)
{
check(QueuedCmdList.CmdList);
// Accumulate dispatch ready events into the WaitOutstandingTasks list.
// This is used by FRHICommandListImmediate::WaitForTasks() when the render thread
// wants to block until all parallel RHICmdList recording tasks are completed.
WaitOutstandingTasks.Add(QueuedCmdList.CmdList->DispatchEvent);
}
if (ParallelTranslatePriority != ETranslatePriority::Disabled && GRHISupportsParallelRHIExecute && IsRunningRHIInSeparateThread())
{
// The provided RHI command lists will be translated to platform command lists in parallel.
// Commands may already be queued on the immediate command list. These need to be executed
// first before any parallel commands can be inserted, otherwise commands will run out-of-order.
ExecuteAndReset(false);
InitializeImmediateContexts();
struct FTask
{
FGraphEventRef Event;
TArrayView<FRHICommandListBase*> InCmdLists;
TArray<IRHIPlatformCommandList*, TInlineAllocator<GetRHIPipelineCount()>> OutCmdLists;
FRHIDrawStats Stats;
};
uint32 NumTasks = 0;
TArrayView<FTask> Tasks = AllocArrayUninitialized<FTask>(CommandLists.Num());
const bool bMerge = !!CVarRHICmdMergeSmallDeferredContexts.GetValueOnRenderThread();
for (int32 RangeStart = 0, RangeEnd = 0; RangeStart < CommandLists.Num(); RangeStart = RangeEnd)
{
(...)
// Gather the list of active pipelines and prerequisites for this batch of command lists
FGraphEventArray Prereqs;
for (int32 Index = 0; Index < NumCmdListsInBatch; ++Index)
{
FRHICommandListBase* CmdList = CommandLists[RangeStart + Index].CmdList;
Task.InCmdLists[Index] = CmdList;
Prereqs.Add(CmdList->DispatchEvent);
}
(...)
// Start a parallel translate task to replay the command list batch into the given pipeline contexts
Task.Event = FFunctionGraphTask::CreateAndDispatchWhenReady(
[&Task, GPUStatsInitial = PersistentState.Stats]()
{
FOptionalTaskTagScope Scope(ETaskTag::EParallelRhiThread);
SCOPE_CYCLE_COUNTER(STAT_ParallelTranslate);
SCOPED_NAMED_EVENT(FParallelTranslateCommandList_DoTask, FColor::Magenta);
TRHIPipelineArray<IRHIComputeContext*> Contexts = {};
// Replay the recorded commands. The Contexts array accumulates any used
// contexts depending on the SwitchPipeline commands that were recorded.
for (FRHICommandListBase* RHICmdList : Task.InCmdLists)
{
// Redirect the output stats to this parallel task's copy
FPersistentState::FGPUStats Stats = GPUStatsInitial;
Stats.Ptr = &Task.Stats;
RHICmdList->Execute(Contexts, &Stats);
delete RHICmdList;
}
// Convert the completed contexts into IRHIPlatformCommandList instances.
// These are submitted by the RHI thread waiting on this translate task.
for (IRHIComputeContext* Context : Contexts)
{
if (Context)
{
IRHIPlatformCommandList* CommandList = GDynamicRHI->RHIFinalizeContext(Context);
if (CommandList)
{
Task.OutCmdLists.Add(CommandList);
}
}
}
}
, QUICK_USE_CYCLE_STAT(FParallelTranslateCommandList, STATGROUP_TaskGraphTasks)
, &Prereqs
, ParallelTranslatePriority == ETranslatePriority::High
? CPrio_FParallelTranslateCommandListPrepass.Get()
: CPrio_FParallelTranslateCommandList.Get()
);
}
// Resize the tasks array view to how many tasks we actually created after merging
Tasks = TArrayView<FTask>(Tasks.GetData(), NumTasks);
// Finally, add an RHI thread task to submit the completed platform command lists.
// The task blocks for each parallel translate completion, in the order they will be submitted in.
EnqueueLambda(TEXT("SubmitParallelCommandLists"), [Tasks](FRHICommandListBase& ExecutingCmdList)
{
TArray<IRHIPlatformCommandList*> AllCmdLists;
for (FTask& Task : Tasks)
{
if (!Task.Event->IsComplete())
{
SCOPE_CYCLE_COUNTER(STAT_ParallelTranslateWait);
Task.Event->Wait();
}
AllCmdLists.Append(Task.OutCmdLists);
ExecutingCmdList.PersistentState.Stats.Ptr->Accumulate(Task.Stats);
Task.~FTask();
}
if (AllCmdLists.Num())
{
GDynamicRHI->RHISubmitCommandLists(AllCmdLists, false);
}
});
}
else
{
// Commands will be executed directly on the RHI thread / default contexts
(...)
}
}