
Preface
在RTR中,全局光照通常只考虑多一次的Bounce,也就是说只计算直接光照和一次Bounce的间接光照
注:关于直接光照、间接光照以及其他基础概念,可参考本博客GAMES101知识梳理
Global Illumination in 3D
Reflective Shadow Maps(RSM) 反射阴影贴图
基本思想
首先,RSM方法基于如下两个观察:
- Q1: 当我们求点的间接光照时,哪些点应该作为次级光源(Secondary Light Source)?
Hint: 这个问题可以很自然地转化为:哪些点被Primary Light Source直接照到?因此,Shadow Mapping就能告诉我们结果 - Q2: 当我们确定次级光源后,如何确定各个次级光源对当前的点p的贡献呢?
Hint: 首先,我们知道次级光源有一定方向,并且是个area light。在GAMES101的Path Tracing部分,为了减少对Tracing不到光源的Path的计算,我们引入了对光源采样的方法。这里也可以用类似的方法计算出各个次级光源对点p的贡献
实现细节
Q1
Shadow Map中,每一个像素都代表了实际场景中的一小片区域,于是Shadow Map中每一个像素描述的小区域都可以很好地作为一个次级光源,间接光照就是计算用这么多个次级光源照亮场景。
RSM假设所有Reflector都是Diffuse的,这样就可以不用考虑不同Shading Point看向次级光源时观察方向不一致的问题
注:此处Reflector指的是次级光源
Q2
辐射度量学的基本概念详见GAMES101知识梳理:光线追踪 - 辐射度量学部分
如前所述,将计算每一个Shading Point的次级光源渲染结果时,通过变量替换的方式将对采样改为对次级光源采样,于是原先渲染方程中对立体角的积分就改写成了对次级光源的面积积分。
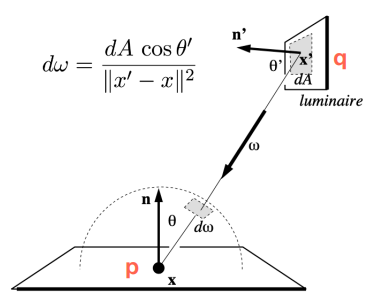
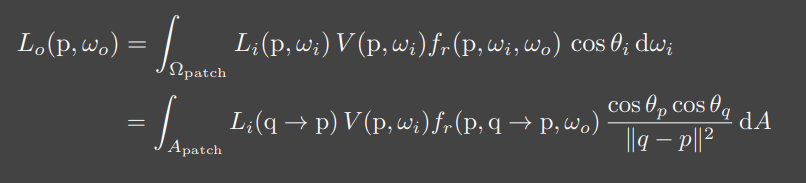
为了计算上述渲染方程,我们需要计算出
对于每一个点q,由于前面假设其为Diffuse,于是其BRDF是个常量:
其中,为albedo。于是
上式表示,当前点p接收到的来自于点q的Radiance为,它等于点q的BRDF乘以点q接收到的Irradiance-,而Irradiance又可以写成RadianceFlux(Energy)除以Area,所以
将上式代回对光源采样的渲染方程,发现被消掉了,而剩下的通常俗称Reflected Flux,这样对于每个点q可以少存储一个量,当然存这个量也没太大关系,算是一个小优化
我们注意到,上面的渲染方程中还有visibility项,而这个visibility项很难计算,因为我们不可能对于每个次级光源都生成一个Shadow Map,这将是一个指数增长的计算量
不好算怎么办?emmm…就不算了…是的,RSM中假设点p与点q之间无遮挡
其实我觉得理论上说这样也没什么问题,反正都是间接光照,实际上就算被挡住了也很可能会有更多次Bounce后的间接光照到达点p,只是RSM中只计算一次Bounce而已
尽管如此,RSM中还是认为,并非所有次级光源都会对Shading Point有所贡献
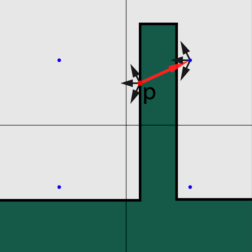
论文说明了几种情况,比如下图中,所在patch应该在桌面上,而点位于所在patch负法线方向半球范围内,对于一次Bounce来说,所在patch不会贡献到点,因此不用计算。
![]()
除此之外,次级光源与Shading point距离过远也被认为不会有所贡献
但是如果对每个Shading Point和每个次级光源都计算一次世界坐标下的距离,那开销是很恐怖的,为了加速该过程,RSM将Shading Point投影到Shadow Map,如果在Shadow Map上Shading Point和次级光源距离较近,就认为在实际的世界坐标下也较近,这又是一个大胆的假设
在此基础上,也可以引入类似PCSS的方法,将Shading Point投影到Shadow Map后,在一定的领域内做范围查询,同时也可以进行采样来进一步加速
其他说明
游戏中对于手电筒灯光通常比较倾向于使用RSM,因为其覆盖范围较小,不需要很大的开销

Pros of RMS:
- Easy to implement
Cons of RMS: - Performance scales linearly w/ #lights
- No visibility check for indirect illumination
- Many assumptions: diffuse reflectors, depth as distance, etc.
- Sampling rate / quality tradeoff
Light Propagation Volumes(LPV) 光照传播体
LPV最早由CRYTEK公司在其游戏引擎CryEngine 3中引入,该引擎代表作正是Crysis(孤岛危机)。
基本原理
要计算间接光照,其关键性的问题就是:在任意一个Shading Point获得来自各个方向的Radiance。
首先,引入一个基本概念:Radiance在空间中沿直线传播,且不会发生衰减。
基于上述想法,LPV将场景分割成3D网格,称为Voxel(体素)
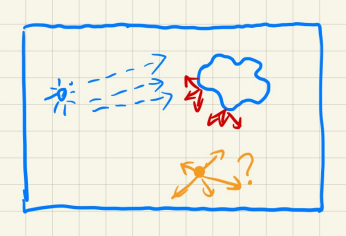
上图将次级光源Radiance的传播描述为红色箭头,每个Radiance都从次级光源所在grid传播到其他grid,那么对于任意一个Shading Point,其获得的来自各方向的Radiance可以描述成从所有次级光源所在grid出发的Radiance传播到达当前Shading Point所在grid的总量。
实现细节
原文的实现步骤是这样说的:
- Generation of radiance point set scene representation;
- Injection of point cloud of virtual light sources into radiance volume;
- Volumetric radiance propagation;
- Scene lighting with final light propagation volume.
说人话就是:
- 获取场景中的次级光源;
- 将次级光源划分到各个网格;
- 在各个网格间传播Radiance;
- 利用传播完成的Radiance进行渲染。
Step1: Generation
这一步是找到所有被光源直接照射到的次级光源(或称虚拟光源),生成次级光源的方法同前文所述的LPV
这里也可以使用采样的方法,减少虚拟光源数量

Step2: Injection
将虚拟光源划分至各个网格,将划分至同一网格的虚拟光源的Directional Radiance叠加,并使用前2阶球谐函数(SH)描述其结果,这一步工业界通常使用一张3D纹理来记录
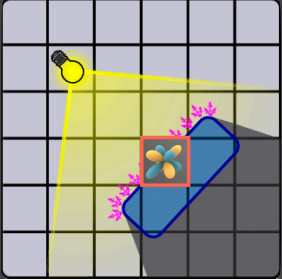
Step3: Propagation
每一个网格中的Directional Radiance都会穿个其六个面传播至相邻网格,对于每个网格做同样的操作,并且将传播完成后的每个网格中的Directional Radiance再次用前2阶SH描述。如此迭代直到网格中的Directional Radiance稳定下来,通常只需4-5此迭代即可稳定
注:这里做了与RSM同样的假设,即不考虑次级光源到Shading Point的Visibility
Step4: Rendering
对于每一个Shading Point,从上述记录网格Directional Radiance的3D Texture中查询该Shading Point所在网格的Radiance,进行渲染
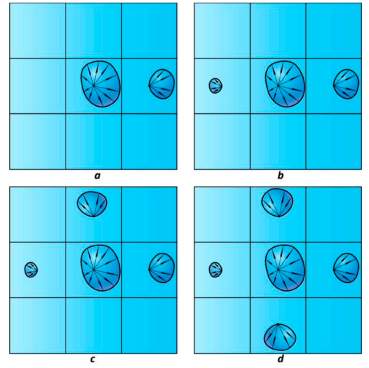
但是此处存在一个问题,由于LPV认为同一网格中的Radiance是Uniform的,因此会出现下图中点p照亮其背面的情况(由于我们只考虑一次Bounce的间接光照,所以任何次级光源都不应该照亮位于其背面的点)
这会导致Light Leaking问题,如下左图建筑的棚顶部作为次级光源照亮了棚子的底下,这种情况尤其多见在物体较小的情况下,因为此时物体的粒度可能比一个grid更小

工业界有用多分辨率网格划分来解决上述问题的方法,称为Cascaded方法
Voxel Global Illumination(VXGI) 体素全局光照
VXGI是一个Two-Pass的算法
注:RTR中Two-Pass算法尤为常见,如Shadow Mapping, RSM,而LPV严格来说是一个Four-Pass的算法
基本原理
同为Two-Pass的算法,VXGI相比RSM有如下两个主要区别:
- Directional illumination pixels -> (hierarchical) voxels
即次级光源最小单位由RSM中的像素变为VXGI中的grids(也就是体素),这些体素可以使用启发式的组织形式,如建立kd-tree, bvh-tree等数据结构以及使用多分辨率的划分形式等等
- Sampling on RSM -> tracing reflected cones in 3D(Note the inaccuracy in sampling RSM)
RSM中第二个Pass计算间接光照从次级光源传播至每一个Shading Point,而VXGI中是从Camera出发Trace向每一个Shading Point,根据每个Shading Point的性质反射出一个圆锥范围,Trace该圆锥可以得到与其相交的Voxel,根据Pass1中计算好的Voxel中的Radiance,便可以算出次级光源对Shading Point的贡献。可见,对于每个Shading Point都需要做一次Cone-Tracing,开销显然比LPV更大
实现细节
Pass 1 from the light
先计算被直接光照照亮的Patches,类似LPV中的injection,将各Patch划分进不同的Voxel,对于每个Voxel都可以计算出总体的入射光与法线分布,根据这两个分布也可以计算出出射光的总体分布,对于这些分布同样也可以使用SH来描述达到压缩的目的
而在启发式算法中,对于建立的树形结构,更高层级的网格可以利用其子节点(更低层级的网格或是其Voxels)的法线分布、入射光分布和出射光分布来计算高层级的总体分布
注:这里初看可以会不理解为什么高层级也需要总体分布的表示,我们Cone-Tracing不是最终要确定与其相交的Voxels吗?其实是这样的:某些情况下一些高层级的网格有可能整个都被我们Trace的Cone给笼罩其中,这种时候可以直接利用该网格的总体分布而无需进一步查询其子节点的分布,更加高效,这才是我们使用启发式算法的主要目的
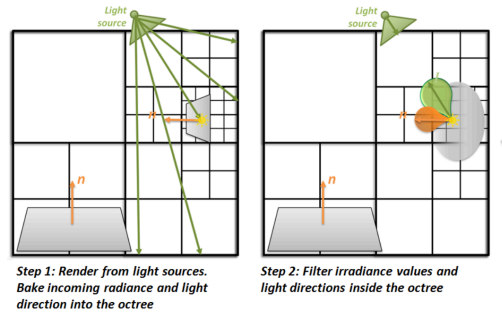
Pass 2 from the camera
Pass 2中,从Camera向Shading Points追踪光线,反射出Cones,每个Cone与场景中的Voxel相交。在传播过程中,Cone会覆盖不断变宽,于是对于不同位置,可以根据Cone覆盖的宽度大小相应地查询不同层级的网格,而无需对每个位置都查询到最叶子节点的Voxels,将各位置查询的结果叠加得到最终结果
注:这个部分可能会有疑惑,乍一看觉得查不同层级最后叠加是不是就重复计算各个Voxels了。其实不然,注意上面的表述——不同位置,结合下右图,找的不同层级位于场景中的不同位置,只要控制合适的步长,查询的每个grid并不会有多大的重叠
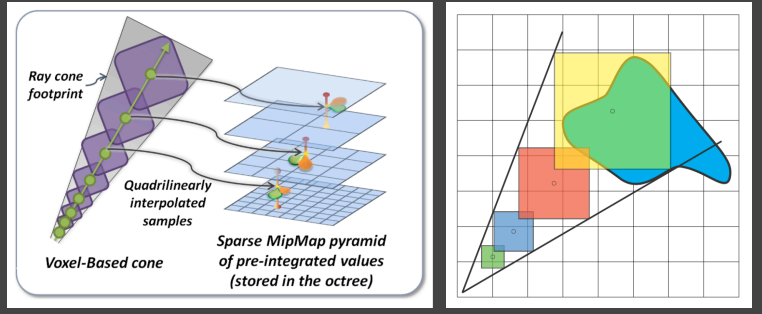
VXGI论文中提出,对于Diffuse材质的Shading Point,与其将其反射情况看成一个覆盖半球的Cone,不如用若干个小Cones组合表示,如下所示,虽然这种表示中有些缝隙,导致表示不完全精准,但是其效果仍是完全可以接受的
补充说明
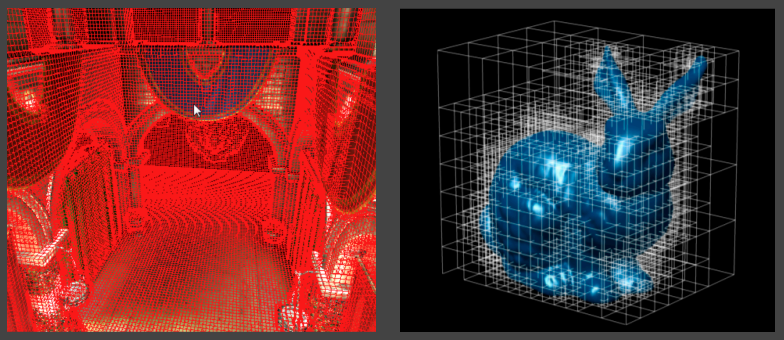
VXGI的效果是很不错的,但是其存在的缺点限制了其应用。VXGI的开销还是略大了一些,而且VXGI要将先场景体素化,如果场景是动态的,则每一帧都需要对场景重新体素化,这将是灾难性的
Global Illumination in Screen Space
在屏幕空间做全局光照,能用的信息就只有从屏幕中来,也就是说,屏幕空间的全局光照开始前可以用到所有信息就是从Camera出发进行直接光照渲染的结果,再换言之,屏幕空间的全局光照就是对于上述直接光照的渲染结果进行后处理
注:RSM严格来说是属于Image Space,将其归为3D空间是为了便于区分,而且RSM中毕竟也有传播过程,也可以勉强算是在3D空间下做的
Screen Space Ambient Occasion(SSAO) 屏幕空间环境光遮蔽
SSAO最早是由Crytek公司(又是它!)引入其游戏引擎CryEngine 2
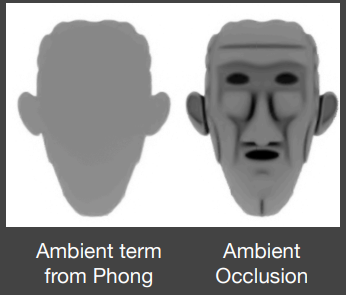
环境光遮蔽就是增强场景中物体之间的Contact Shadow(接触阴影),使得物体之间相对的空间位置感更强
下左图为有AO,右图为没有AO

AO是GI的一种近似,而SSAO就是在屏幕空间中做这种近似
基本原理
在屏幕空间中,我们并不知道各Shading Point接收到的间接光照强度,于是SSAO中假设其为一个常数,这一点与Blinn-Phong模型中的Ambient项的假设相同
SSAO虽然假设Shading Points接收到的来自四面八方的间接光照强度相同,但是假设各方向的Visibility并不相同,也就是Shading Points不见得能接收到来自各方向的光照
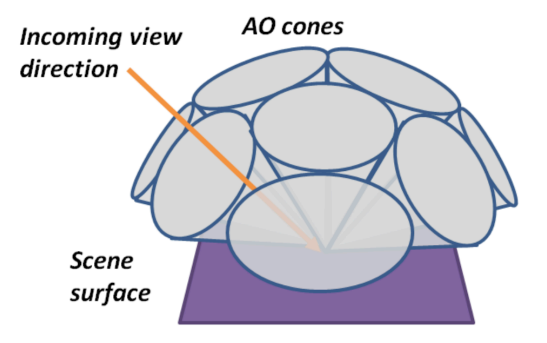
以Uniform的间接光照渲染场景就相当于使用一个纯白的环境光渲染场景,这在3D建模软件中称为天光
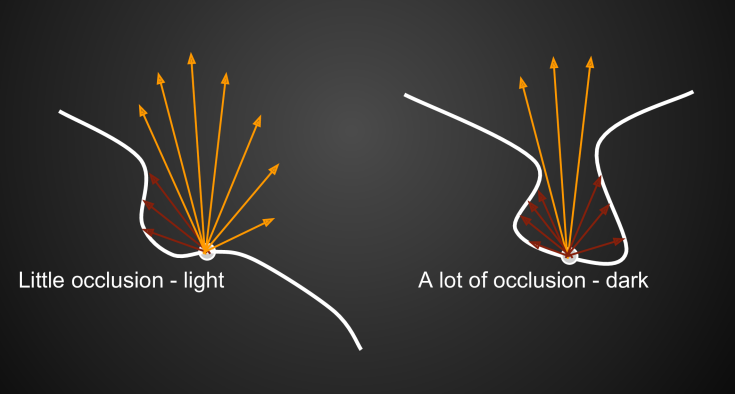
AO可以示意如下,显然,遮挡少的点比较亮,反之则比较暗
再深入些理解,就需要再次请出渲染方程,并且使用之前提到过的RTR中常用的积分近似方法

将Visibility项当成拆出积分,有如下表示形式
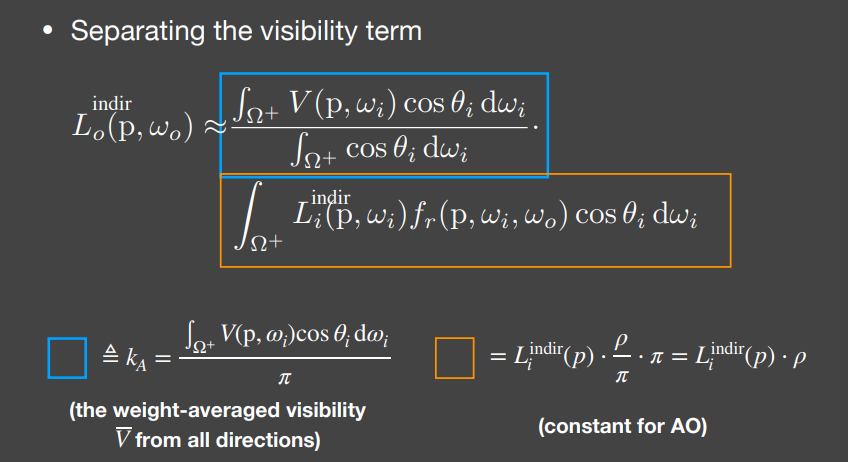
其中,由于我们假设Shading Point接收到的间接光照强度为一个常数,因此就是一个常数,而假设物体为Diffuse的,则BRDF就表示为
进一步理解,上述积分拆分形式的项就是求平均的写法,因此可以直接将其改为
注:之前提到,上述积分近似需要在比较smooth且其support较小。不过在此处,由于是间接光项乘以Diffuse的BRDF,它就是个常数,因此上述近似无论如何都是适用的

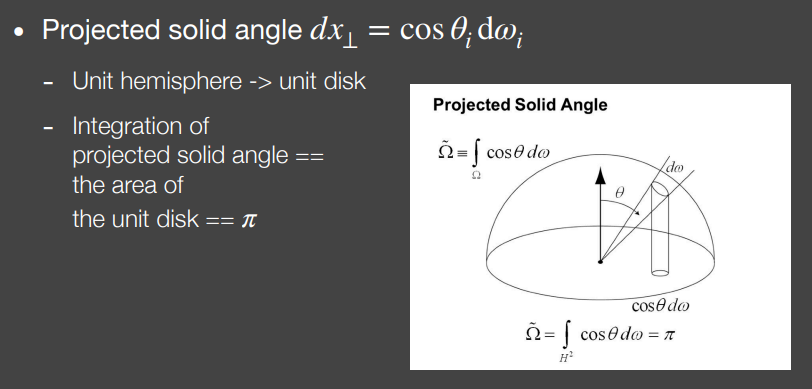
再进一步,我们注意到上面拆出来的Visibility项上下都多了一个,这是为什么呢?
立体角实际上对应的其在单位球面上的面积,而乘以这个实际上是将立体角对应的球面积投影到底面的圆上,上下都做这个投影,实际上就是将原先在单位半球面上的积分变为在单位圆上的积分
上述的推导是为了方便理解,实际的做法则更为简单,由于我们已经假设入射的Irradiance为常数,且使用Diffuse的BRDF,则可以将这两项直接从积分中提出,对剩下部分再进行拆分,这和上面是一模一样的,但是形式上看起来更加简单
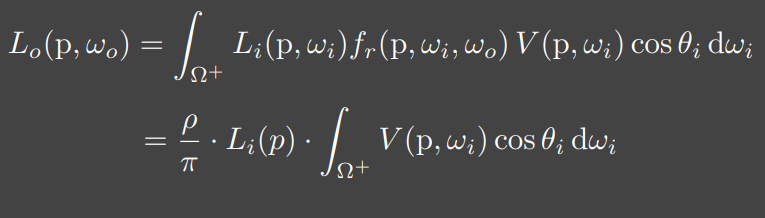
实现细节
在3D中我们可以用Ray-Tracing的方法算出遮挡,但是在屏幕空间中我们拥有的信息十分有限,如何计算遮挡呢?
3D空间和屏幕空间中AO的对比:

首先,遮挡是需要在一定距离范围内进行判断,因为我们通常认为间接光照都是来源于较近的物体反射的直接光照。如果在无限远范围内判断遮挡,那么会多出非常多的方向判断结果为有遮挡导致该方向上的AO为0
但是这种范围限制将超出这种范围但是实际应该存在的AO排除在外
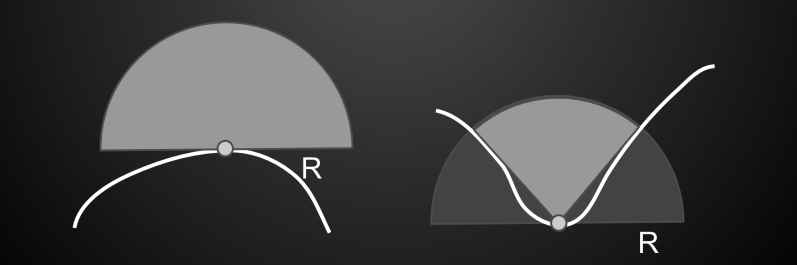
SSAO为了计算当前Shading Point的遮挡情况,假设在以该Shading Point为球心一个固定半径的球体内随机地采样一些点,能够直接从Shading Point出发被看到的点就不是在遮挡物内部,反之则认为该点在遮挡物内部。然后利用这些随机采样点的总体情况来描述该Shading Point的AO的总体情况
SSAO还进行了一个大胆的假设:
首先,我们在渲染时存储了一个从Camera看向场景的深度图。而对于上述的所有采样点,我们都可以将其投影至这个深度图上并将它们的深度与深度图中对应像素记录的深度进行比较,若点深度大于深度图中对应像素的深度,则认为该点在遮挡物中,反之则认为不在遮挡物中
该假设大部分情况下还是比较准确的,但是也会有判断错误的点,如上中图红色虚线右侧的那个点就会被误判为在遮挡物中,但是依然是可以接受的
这里还有一个问题,Shading Point本身就是在物体表面,其所在的微表面负法线方向的一个小半球内的点本就应该被认为是在该物体内部,那么我前面说的对整个球内部进行采样就是不准确的
这个问题可以通过渲染时候记录的Shading Point的法线来解决,我们只采样法线方向的半球内部
不过在SSAO刚刚被提出的时代,尚没有在渲染时同时得到Shading Point法线的标准,因此不能假设在渲染时一定能得到对应的法线。所以SSAO使用了更为简单粗暴的方法,就是对于上述一个Shading Point定义的小球内的所有采样点,如果其判断结果为在遮挡物内的点数超过一半,则认为法线方向半球内有遮挡物,此时才考虑AO问题。当点数不过半时,认为这些点都是负法线方向半球内本就应该是在物体内的点,所以直接忽略
注:上述SSAO方法实际上也没有考虑前面推导的与Visibility项组合的项,因此在物理意义上是不准确的,但其结果依然可以接受
补充说明
SSAO存在一些问题

从上图中圈出的位置可见,地面上有一部分出现了被石凳遮挡出现的AO,但是游戏场景中石凳与其后面的地面相隔距离较长,地面不应该出现AO才对
这个问题是因为,在对地面上出现AO的那些Shading Points周围的小球内部进行上面所说的采样时,有一些采样点会在石凳的后面,当这些点投影会Camera方向记录的Shadow Map时,会查询到对应像素(也就是石凳上)的深度,于是这些点会被判断为在遮挡物内部(然而这些点显然不在地面的遮挡物内),所以地面上那些Shading Points会错误地生成AO
SSAO的上述采样过程也有一些说法,采样点数越多当然越精确,但是也需要与速度进行权衡
通常,可以使用较少量的Samples先得到应该噪声比较多的AO的结果,然后对该结果进行降噪,虽然降噪会使得AO结果变模糊,但是AO正常情况下都是叠加在直接光照等渲染结果上一起看,因此整体效果还是挺不错的

上面提到SSAO提出时,渲染时候还不一定能得到Shading Point的法线,但是现在是可以的。有了这个法线,我们不仅可以只在对应的半球进行采样,还可以将SSAO中没有考虑的项也引入其中,得到比SSAO更好的效果。
这也被称为Horizon Based Ambient Occlusion(HBAO)
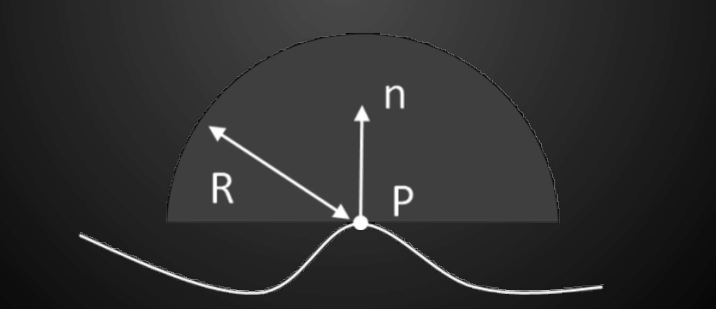
因为HBAO中利用了法线等信息,实际上是能真正在3D空间中考虑一定范围的半球内是否有遮挡(从这点看HBAO或许可以认为是一半3D空间一半屏幕空间的做法),所以也解决了SSAO中错误遮挡的问题
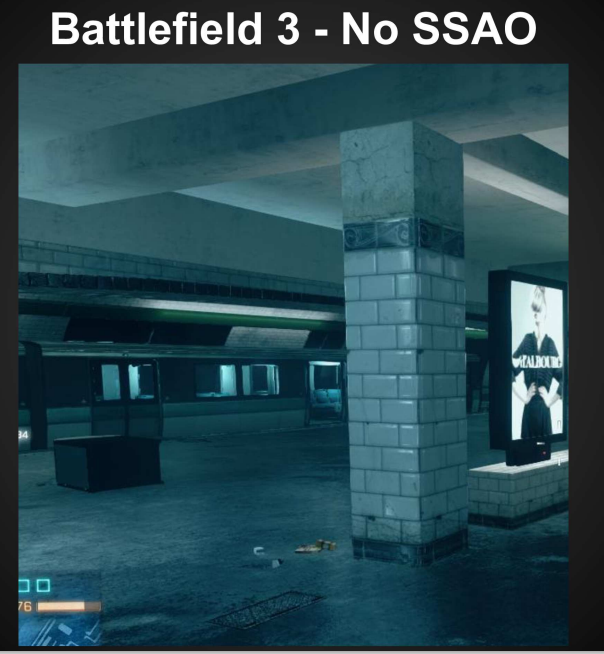
下面是战地3中,不开SSAO、开启SSAO和开启HBAO的效果


Screen Space Directional Occlusion(SSDO)
SSDO是对SSAO的一种改进
基本原理
SSDO基于如下基本思想:
不必假设Shading Point上入射的各方向的间接光照强度都相同,因为次级光源的部分信息我们是可以知道的
不同于RSM中利用光源Shadow Map查找次级光源,SSDO是利用Camera能够看到的次级光源,也就是说其次级光源信息只来源于屏幕空间
SSDO的原理接近Path Tracing,从当前的Shading Point出发,向各方向Trace光线,如果某个方向上光线打到其他物体,则认为该方向会接收其他物体反射而来的间接光照;而如果某方向上没有打到其他物体,则认为该方向上接收到的是直接光照
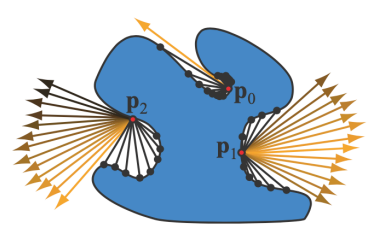
对比SSAO可以发现,SSAO与SSDO的假设实际上是相反的
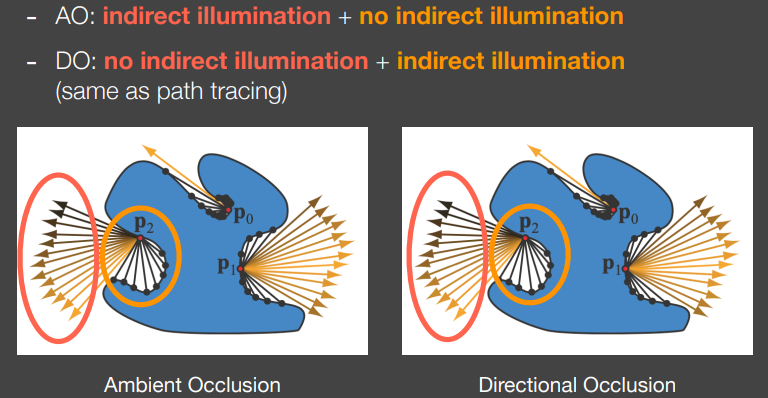
SSAO认为图中红圈内没有打到其他物体的方向没有被遮挡,因此可以接收到间接光照,而橙色圈内的被遮挡则接收不到间接光照;
SSDO认为图中红圈内没有打到其他物体的方向上没有次级光源,因此不会有间接光照,而橙色圈内的方向打到的遮挡物则正是其间接光照的来源。
导致这种相反假设的原因是,SSAO假设间接光照来自于距离Shading Point较远的地方,而SSDO假设间接光照来自于距离Shading Point较近的地方。
实现细节
SSDO也同样是将渲染方程分为直接光照与间接光照两部分来计算,关于各个次级光源对Shading Point的贡献,计算方法同RSM,此处不再赘述
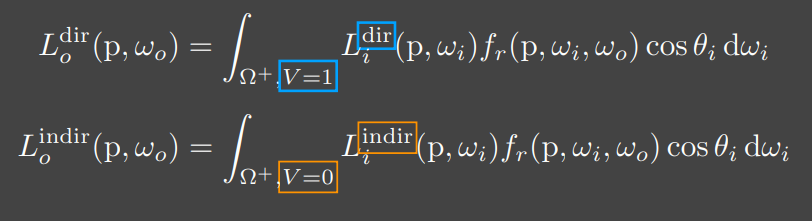
SSDO中,寻找对当前Shading Point有贡献的次级光源的方法与HBAO相同。在Shading Point法线方向半球中随机采样若干点,判断这些点与Shading Point之间是否有遮挡。
但是,这里仍然不直接判断遮挡,依然使用了之前大胆的假设,即将采样点对于Camera深度与其在Camera的Shadow Map上对应的像素深度进行对比,如果采样点的深度大于Shadow Map对应像素的深度,则视为遮挡(如图中A,B,D);反之,则视为未遮挡(如图中C)。
对于判为遮挡的点,可以通过Shadow Map对应像素的深度找到其对应的次级光源Patch,利用Patch的法线方向以及先前计算完成的直接光照情况,计算出每个Patch对Shading Point的贡献,相加得到Shading Point的间接光照
而对于图中C点这种未遮挡的点,可以沿着其方向查询环境光照
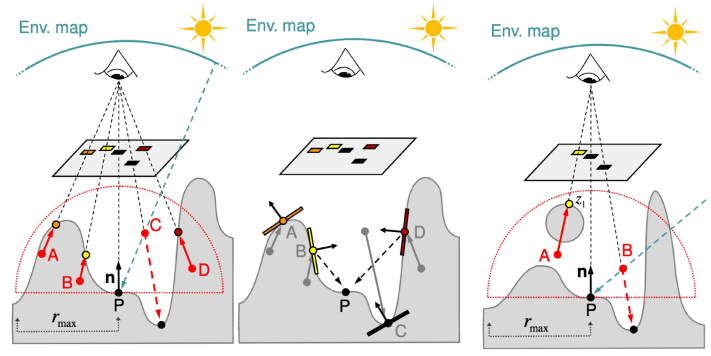
当然,由于依旧使用了上述大胆的假设,因此依然会出现某些错误,如右图中A点就会判断错误
补充说明
Pros & Cons
Pros:
- 能够做到近乎离线渲染的全局光照质量
Cons:
- SSDO是一个小范围的全局光照
- 因为上述的大胆假设,因此Visibility并不完全准确
- SSDO最大的问题在于其基于屏幕空间。而某些在屏幕空间中看不到的,位于更大深度的物体也可能作为次级光源贡献到Shading Point,这部分信息会丢失
Screen Space Reflection(SSR) 屏幕空间反射
SSR也是一种在RTR中实现全局光照的方法,它可以在屏幕空间中实现光线追踪,而不需要知道3D中的片元信息
SSR也可以理解为Screen Space Ray-Tracing
SSR主要有两个基本任务:
- Intersection: 求任意光线与Camera下可以看到的场景物体的交点;
- Shading: 计算各交点对Shading Point的贡献
基本原理
很多情况下,反射出来的物体大多是当前Camera能够看到的东西,因此即便不加入Screen Space下看不到的物体,也能做出较好的反射效果。
SSR就是利用Screen Space上拥有的场景信息完成反射的计算

以镜面反射为例,一个比较粗糙的SSR实现方法大致如下:
- 根据入射方向和Shading Point法向量计算出射方向;
- 沿着出射方向Trace光线,计算出Screen Space内与其相交的点(利用深度);
- 将交点的颜色作为反射的颜色。

除了Specular材质,SSR也可以对Glossy等其他材质以及更复杂的法线分布情况计算反射
高光滑程度

中等光滑程度
注:Glossy材质的BRDF分布在一个Lobe里,因此实现SSR时可以在Lobe内计算多条反射光线

中等光滑程度 + 不同法线分布

各不相同的光滑程度

实现细节

根据上述分析,SSR中最重要的是反射光线与Screen Space中的场景求交
一个简单的做法就是使用RayMarch,每一次向反射方向Trace一定的步长,对于新Trace到的点可以算得其深度,将该点投影至Camera的Shadow Map上,并与Shadow Map上对应像素的深度比较。若点的深度小于Shadow Map上对应的深度,则认为还没Trace到物体;反之,则认为以及打到物体。(这里利用深度来判断的思路与SSAO类似)
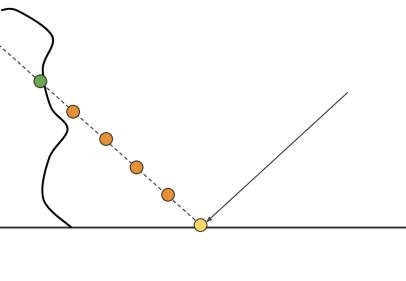
RayMarch的质量与其步长有很大联系。若步长取太大,则有可能判断Trace到的点打到物体时,该点已经进入物体内部一段距离了;而步长取的太小,则迭代次数会变多,开销变大
注:此处的步长是一个定值,因为没有SDF来指导我们还有多少安全距离,因此无法自适应地调整步长。这是一种盲目向前试探的方法
但是我们依然想要一种可以使用动态步长的方法
这里引入一种层级式的Ray Trace方法
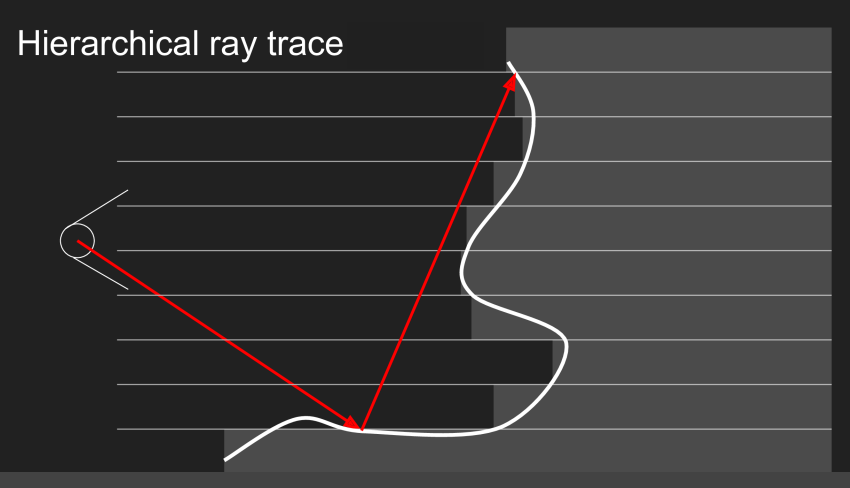
我们注意到,很多时候是没有必要一小步一小步地向前试探的。如果可以快速地向前走大步,在即将Trace到物体时再逐渐变成小步试探,那么可以大大提高速度
这种层级式的方法有一个前置准备,就是将Camera场景深度做MipMap
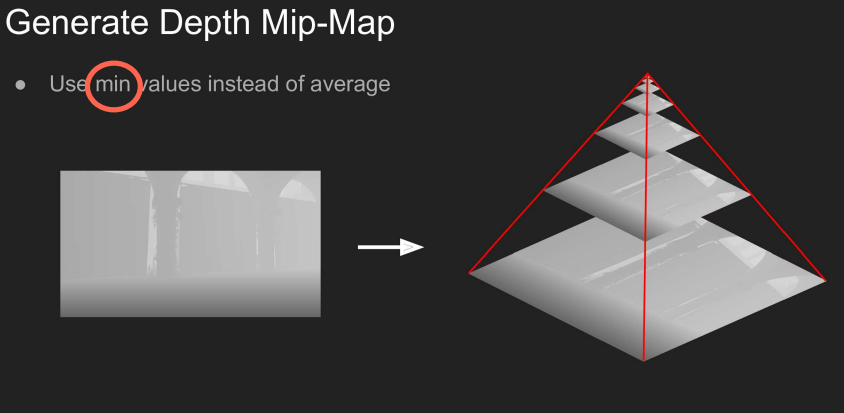
不过,这个MipMap与我们在Texture Mapping里使用的MipMap有一些区别。
这里的MipMap上层像素记录的并不是下层对应四个像素的平均值,而是最小值,实际上就是深度学习中常见的最小池化。
这里为什么要使用最小值呢?
可以类比BVH来理解。构建BVH的目的是使我们判断光线与当前的AABB不会相交时,能够快速跳过与该AABB内的所有物体求交,因此AABB的边界要取其中物体最外的边界。通俗理解就是,如果光线不与父节点AABB相交,则更不可能与其子节点AABB或其中的物体相交了。
这里MipMap的目的是使我们判断与这个层级的Block不相交时,可以快速跳过与这个层级内的所有像素比较深度,因此这个层级的深度要取其中像素最边界的深度,也就是最小值。通俗理解就是,如果光线与上层的Block,就更不可能与其下层中的Block或是其中的像素相交了
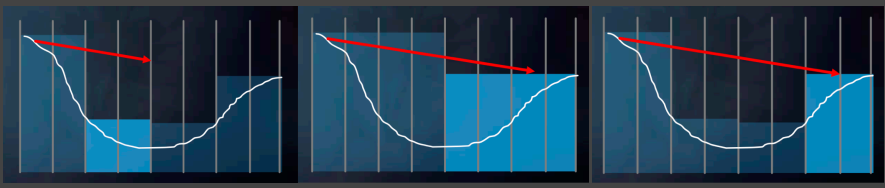
使用MipMap求交点的伪代码如下:
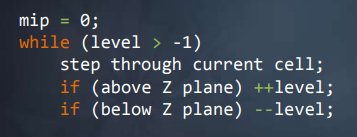
这个算法用一句话概况就是:在危险的边缘疯狂试探
这步走完发现没撞上,下一步就走大一点,如果下一步会撞,就减小步子
注:这里通常认为与当前层级的Block相交时,我们可以确定会与其哪个子节点相交,而不用分别对其两个子节点进行求交判断
SSR在Shading阶段依然假设次级光源是Diffuse的

从Shading Point出发Trace到的点发出的Radiance,就是Shading Point接收到的该点的Radiance
注:这里不存在距离衰减;同时因为SSR是一种Ray-Tracing,所以可以处理好Visibility问题
补充说明
如同其他在Screen Space中实现的方法,SSR也存在Screen Space导致的各种问题
Hidden Geometry Problem
即对于屏幕空间中看不到的物体,没法正常求出其反射
如下图中,虽然地面反射出了手掌,但是并不完整,可以看到反射出来的手掌的指腹部分有所缺失,因为指腹在屏幕空间中看不到,SSR自然没法利用这些看不到的信息完成反射

Edge Cutoff
如同在屏幕空间中因为遮挡而看不到的物体的存在是SSR所无法知晓的,SSR同样并不知道屏幕空间范围外物体的存在
如下图可以看见,窗帘的上部在屏幕之外,因此反射出来的窗帘无法包含屏幕之外的上半部分,因此出现了截断

对于这种问题,人们通常认为Trace距离越远的点,其反射程度越小,其对应的反射结果则会更加虚化,这样上面窗帘离地面越远的部分反射越虚化。这样可以一定程度上解决上述边缘截断的问题

SSR可以满足我们对反射的很多预期效果,这些也是实际中会出现的

上述四个效果通俗解释就是:
- 清晰和模糊的反射
- 物体与反射物接触处的反射更清晰
- 反射拉长
- 对于每个点定义不同的粗糙程度与法线分布
一些改进
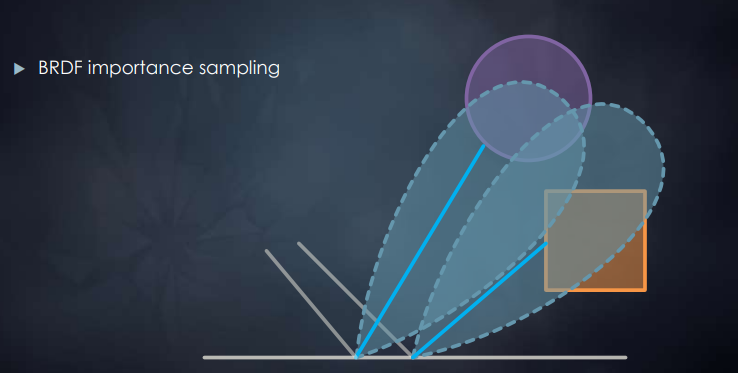
BRDF重要性采样
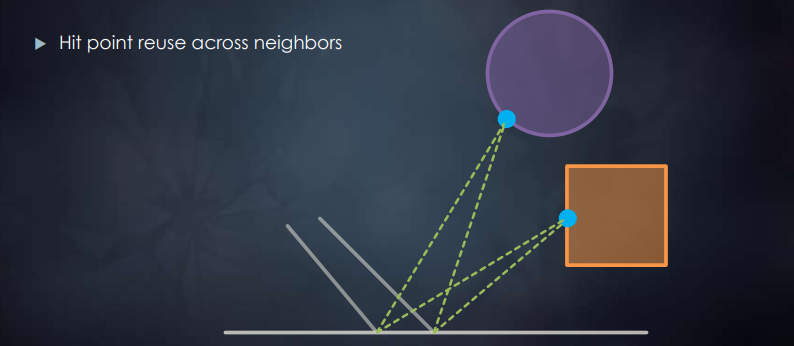
临近交点的复用
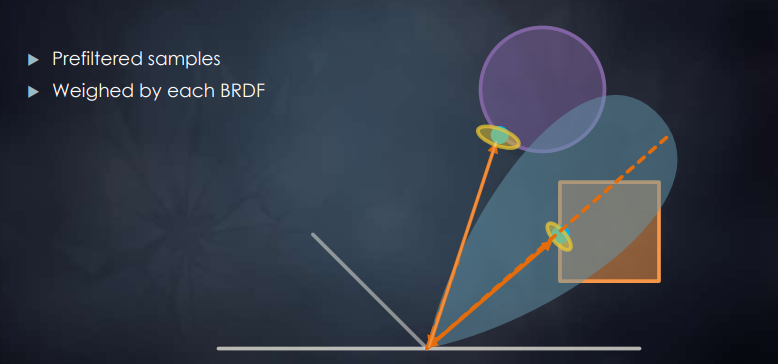
Pre-Filtering(类似Split-Sum)
Pros & Cons
